block storage
What is block storage?
Block storage is an approach to data storage in which each volume acts as an individual hard drive that is configured by the administrator.
In the block storage model, data is saved to the storage media in fixed-sized chunks called blocks. Each block is associated with a unique address, and the address is the only metadata assigned to each block.
To manage block storage, a software program independent of the storage media controls how the blocks are placed and organized across storage drives. The software also handles data retrieval, using metadata to locate the desired blocks and then organizing the data in them into complete files.
Storage blocks are controlled by the server-based operating system and are generally accessed by iSCSI, Fibre Channel or Fibre Channel over Ethernet protocols. Block storage is ideal for high-performing, mission-critical applications that require consistent input/output performance and low latency and is often used in storage-area network (SAN) environments in place of file storage.
Because block storage plays a critical role in many enterprise applications, some cloud vendors offer block storage services in addition to their object storage services. Popular block services in the cloud include Amazon Elastic Block Store (EBS), Google Cloud Persistent Disks and Rackspace Cloud Block Storage.
Block storage uses
Block storage has remained primarily on premises, supporting mission-critical and data-intensive workloads. But this appears to be changing. Increasingly, organizations are turning to the cloud for block storage as they look for more efficient and flexible ways to support their workloads.
Because block storage volumes are treated as individual hard disks, the approach works well for storing a variety of applications:
- Email servers such as Microsoft Exchange use block storage in lieu of file- or network-based storage systems.
- With RAID arrays, multiple independent disks are combined for data protection and performance. The ability of block storage to create individually controlled storage volumes makes it a good fit for RAID.
- Virtualization vendors such as VMware support block storage protocols, which can improve migration performance and improve scalability in VM file systems. Using a SAN for block storage also aids VM management, enabling non-standard SCSI commands to be written.
Block vs. file storage
While there are benefits to using block storage, there are also alternatives that may be better suited to certain organizations or uses. Two options stand out when it comes to facing off with block-level storage: file storage and object storage.
If simplicity is the goal, file storage may win out over block-level storage. But while block storage devices tend to be more complex and expensive than file storage, they also tend to be more flexible and provide better performance.
File storage provides a centralized, highly accessible location for files, and generally comes at a lower cost than block storage. File storage uses metadata and directories to organize files, which makes it a convenient option for an organization looking to simply store large amounts of data.
The relatively easy deployment of file storage makes it a viable tool for data protection, and the low costs and simple organization can be helpful for local archiving. File sharing within an organization is another common use for file storage.
The simplicity of file storage can also be its downfall. While it has a hierarchical organization to it, the more files added, the more difficult and tedious it becomes to sift through file storage. If performance is the deciding factor, object or block-level storage wins out over file storage.
Some products, such as Hewlett Packard Enterprise (HPE) 3PAR File Persona Software, have converged file and block storage to provide the benefits of both technologies.
Block vs. object storage
Rather than splitting files into raw data blocks, object storage clumps data together as one object that contains data and metadata. Blocks of storage do not contain metadata, so in that regard object storage can provide more context about the data, which can be helpful in classifying and customizing the files. Each object also has a unique identifier, which makes quicker work of locating and retrieving objects from storage.
Block storage can be expanded, but object storage is unmatched when it comes to scalability. Scaling out an object storage architecture only requires adding nodes to the storage cluster.
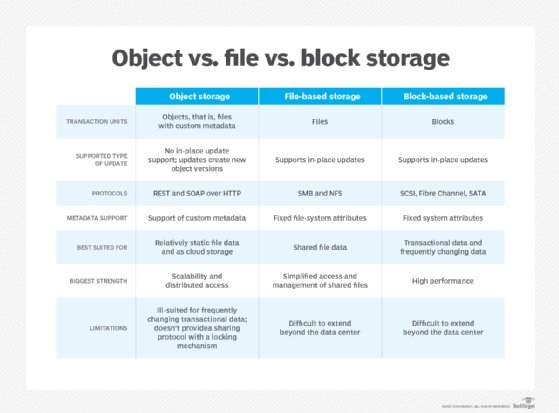
The flexibility and scalability of object storage may be appealing, but some organizations may wish to prioritize performance and choose file or block storage. While block storage enables editing incremental parts of a file, object stores must be edited as one unit. If one part of an object needs to be edited, the entire object must be accessed and updated, then rewritten, which can negatively affect performance.
Both object and block-level storage are used in the enterprise, but object storage use cases lean more toward scenarios dealing with large amounts of data, such as big data storage and backup archives. Because of this, modern data storage environments such as the cloud are arguably trending toward object-based storage over file and block storage options. However, individual needs will always be the determining factor for which form of storage is used.
Block storage vendors
Along with HPE, several larger and smaller storage vendors provide block storage. The largest storage vendors are Dell, Hitachi Vantara, IBM and NetApp. Additional vendors include DataDirect Networks, Huawei, Infinidat, Nutanix, Oracle, Pure Storage, Tintri and Western Digital. The largest vendors all have several block storage platforms, as well as unified storage that runs block and file on the same arrays.
OpenStack Block Storage (Cinder) is an open source form of block storage, which provisions and manages storage blocks. It also provides basic storage capabilities such as snapshot management and replication. OpenStack Block Storage is supported by other vendors such as IBM, NetApp, Rackspace, Red Hat and VMware.
Amazon EBS is persistent block storage for Amazon Elastic Compute Cloud. EBS is scalable and designed for workloads such as big data analytics, NoSQL databases and data warehousing.
Why block storage is gaining momentum
With large vendors like Dell and Amazon on board with block storage products, it is clearly going to be a supported technology for the foreseeable future. While there are pros and cons to its use, many of the negatives can be chalked up to features that are better provided by a different storage system. These needs may vary by organization, and while file or object storage may be better suited to some cases, block storage will likely be the right choice for others.
If an organization is looking to incorporate the cloud, then they will find block storage to be a common partner for cloud computing.
The main disadvantage to SAN environments, where block storage systems are most often found, is the cost and complexity associated with building and managing the environment. As long as organizations are willing to take on those obstacles, SAN environments will remain a viable option. With virtual and converged SAN options on the market today, SAN arrays -- and block storage with them -- are likely to continue to grow and meet consumer needs.
Editor's note: This article was revised in 2023 by TechTarget editors to improve the reader experience.






