Part of:Analyze object storage vs. other key storage types
Understanding object storage vs. block storage for the cloud
The use of block storage in the cloud is becoming more common. See how block and object storage differ, and when to use one versus the other when it comes to cloud storage.
Cloud storage services have exploded in the last decade, largely due to the proliferation of low-cost object-based repositories, which have proven ideal for many of today's hyperscale workloads. Block storage, on the other hand, has remained primarily on premises, supporting mission-critical and data-intensive workloads. But this appears to be changing. According to two recent Taneja Group studies, organizations are increasingly turning to the cloud for block storage as they look for more efficient and flexible ways to support their workloads.
For many decision-makers, the difference between cloud object storage vs. block storage and when to use one or the other isn't always clear. Only by understanding both approaches can you plan an effective strategy for adopting cloud storage in your organization.
Block storage basics
Block storage is one of the oldest and most commonly used types of storage, and it continues to support many of today's applications. Although it has traditionally been associated with on-premises SANs, block storage is now very much a part of the cloud landscape, with more providers than ever offering block-based services.
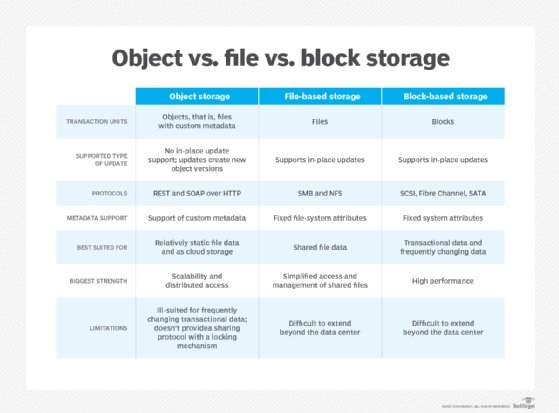
In the block storage model, data is saved to the storage media in fixed-sized chunks, or blocks, of raw storage volumes. Each block is associated with an address that uniquely identifies the block. This address constitutes the only metadata assigned to the block, and some industry experts don't even consider these addresses to be metadata.
Because of the lack of metadata, blocks are lean and efficient, without a lot of overhead to weigh them down. To manage block storage, a software program independent of the storage media controls how the blocks are placed and organized across the storage drives. The software also handles data retrieval, using the addresses to locate the blocks and then organizing the data into complete files.
Block storage has long been the go-to solution for enterprise storage because it is fast, efficient and flexible, with low-latency I/O and high reliability. Block storage devices can be easily detached and moved, and the technology behind it is well known and highly implemented, making it easier to integrate block storage into a variety of application workflows.
Organizations are increasingly turning to the cloud for block storage as they look for more efficient and flexible ways to support their workloads.
That said, when considering the object storage vs. block storage choice, it's important to consider the challenges block storage presents. These include limited scalability and increased latency, which can occur when the controlling application isn't in proximity to the storage devices. The lack of metadata can be a disadvantage, because it puts the onus on the controlling application to attach additional information to each block if it's needed. Block storage can also get expensive and can be complex to maintain and optimize.
Despite these challenges, block storage is well suited to several enterprise use cases. It's ideal for high-performing, mission-critical applications that require consistent I/O performance and low latency, such as relational database systems, virtual desktop infrastructures and email servers. It's also well-suited to RAID arrays and can support system booting from network storage.
Because block storage plays such a critical role in so many enterprise applications, it's no surprise that cloud vendors now offer block storage services, such as AWS Elastic Block Storage, Google Cloud Persistent Disks and Rackspace Cloud Block Storage.
With object storage, data and its metadata are packaged into discrete units, or objects, that are stored within a structurally flat data environment, which can span multiple network systems and geographic boundaries. To access the data, applications need only use common HTTP-based RESTful API calls, such as PUT, GET or POST, simplifying the process of accessing and managing data.
The metadata associated with each object includes a unique identifier, and it can include customizable information that provides more context to the underlying data. For example, the metadata might include details about the corresponding application, the level of data protection to assign to the object or other information that supports policies for retaining, routing and deleting data. Effective metadata can also be instrumental in performing advanced analytics.
The object model's flat structure and customizable metadata make the process of scaling data repositories simpler. When you require more storage, you need only deploy additional nodes, even across geographic boundaries. In addition, the customizable metadata makes it easier to organize, search and retrieve data across locations. Object storage services tend to be less expensive than other storage services because the storage can run on commodity hardware, is easier to manage and in many cases isn't accessed as often.
But object storage has its own challenges, most notably performance issues. The metadata can add overhead, and data modifications can be cumbersome. Even read operations can be slow because of the inherent latencies. In addition, an organization moving to object storage might need to update its applications to accommodate the HTTP calls.
Even with these challenges, however, object storage is an advantage in many use cases. For example, it's well suited to storing large volumes of unstructured data that's infrequently updated. Object storage also is a good fit for backing up or archiving data, as well as for large-scale analytics that can take advantage of the rich metadata. In addition, many organizations use object storage for web applications and services, which are naturally suited to using the HTTP calls for accessing the stored objects.
Many cloud providers now offer object storage services, including those that also provide block services. Amazon, Rackspace and Google all offer both object storage and block storage cloud services.
Object, block and file storage
Making the object storage vs. block storage choice
Both block and object storage have their advantages and disadvantages, with most use cases falling into one camp or the other. You probably won't use object storage to support your relational databases, but you might use it to for your global web applications or big data analytics projects. Fortunately, the object storage vs. block storage decision is getting easier as cloud providers now offer multiple options for storing data. These options make it easier to move enterprise workloads to the cloud, without compromising the performance of mission-critical applications.