Videos
Photo Stories
-
Speeds of storage networking technologies rise as flash use spikes
-

Keep tabs on the following data storage startup vendors in 2017
-

Five ways VDI technology is affected by storage
-
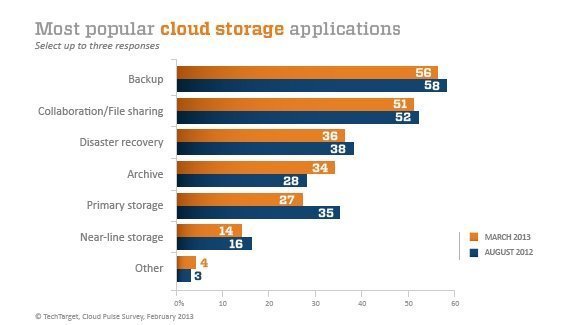
Survey finds cloud storage implementation growing but cautious
-

Data storage companies focus on flash M&A potential
Podcasts
-

Storage Spaces Direct a key option in Windows Server 2016 features
-
A tiered storage model is different from caching
-
How NAND flash degrades and what vendors do to increase SSD endurance
-
Erasure coding tradeoffs include additional storage, disk update needs
-
Erasure coding brings trade-off of resilience vs. performance
-
Wikibon CTO: Erasure coding can help reduce data backup costs