OpenStack
What is OpenStack?
OpenStack is a collection of open source software modules and tools that provide organizations with a framework to create and manage both public cloud and private cloud infrastructure. It's considered one of the most active open source projects worldwide.
OpenStack delivers infrastructure-as-a-service (IaaS) functionality -- it pools, provisions and manages large concentrations of compute, storage and network resources. These resources, which include bare-metal hardware, virtual machines (VMs) and containers, are managed through application programming interfaces (APIs), as well as an OpenStack dashboard. Other OpenStack components provide orchestration, fault management and services intended to support reliable, high availability operations.
Businesses and service providers can deploy OpenStack on premises in the data center to build a private cloud, in the cloud to enable or drive public cloud platforms, and at the network edge for distributed computing systems.
What does OpenStack do?
The main purpose of OpenStack is to create and deploy a cloud computing environment. An organization typically creates a cloud computing environment by building off its existing virtualized infrastructure, using a well-established hypervisor, such as Microsoft Hyper-V, VMware vSphere or Kernel-based Virtual Machine. However, cloud computing offers more than just virtualization; a public or private cloud provides extensive provisioning, lifecycle automation, user self-service, cost reporting and billing, orchestration and other features.
Installing OpenStack software on top of a virtualized environment forms a cloud operating system (OS). An organization can use that to organize, provision and manage large pools of heterogeneous compute, storage and network resources. Whereas an IT administrator typically provisions and manages resources in a more traditional virtualized environment, OpenStack lets individual users provision resources through management dashboards and an API.
This cloud-based infrastructure created through OpenStack supports an array of use cases, including web hosting, big data projects, software-as-a-service delivery and container deployment.
OpenStack competes most directly with other open source cloud platforms and tools, including Apache CloudStack and Eucalyptus. Some organizations consider it an alternative to public cloud platforms, such as Amazon Web Services (AWS) or Microsoft Azure, and some smaller public cloud providers use OpenStack as their native cloud platform.
How does OpenStack work?
OpenStack isn't a cloud application in the traditional sense, but rather a platform composed of several dozen separate components called projects, which interoperate with each other through APIs. Each component is complementary, but not all components are required to create a basic cloud. Organizations can install only select components that build the features and functionality in a desired cloud environment.
OpenStack also relies on the following two additional foundation technologies:
- A base OS. This includes an OS such as Linux that handles the commands and data exchanged from OpenStack.
- A virtualization platform. The virtualization engine manages the virtualized hardware resources that are abstracted from hardware and used by OpenStack projects. Common examples of virtualization software include VMware and Citrix.
Once the OS, virtualization platform and OpenStack components are deployed and configured properly, IT administrators can provision and manage the resource instances that apps require. Actions and requests made through a dashboard produce a series of API calls, which are authenticated through a security service and delivered to the destination component, which executes the associated tasks.
As a simple example, an administrator logs in to OpenStack and manages the cloud environment through a dashboard. They can create and connect new compute instances and storage instances and configure network behaviors. Additionally, an IT admin might connect various other services, such as to monitor the performance of a provisioned instance and employ resource billing and chargeback.
The OpenStack platform's vast scope and sheer number of interrelated components can be confusing and even daunting. Most OpenStack adopters start with a small number of essential components and gradually deploy other components over time to build out their cloud's operational and business capabilities.
Who uses OpenStack?
Because of its flexibility and open source nature, OpenStack appeals to a wide range of users. The following are examples of industries and institutions using OpenStack:
- Telecommunications companies. Telecommunications companies and service providers, such as Telefônica Brazil, use OpenStack to develop and administer their own clouds.
- IT and services industries. Many organizations in the IT and services industries use OpenStack for their cloud infrastructure needs. Ocado, a global technology-led software and robotics platform and online grocery provider, uses OpenStack's low-latency benefits to power its robotic warehouses and grocery delivery.
- Hardware manufacturers. Fujitsu and Canonical use OpenStack to power their cloud offerings or to establish their own private clouds.
- Financial institutions. Investment banks and financial service providers use OpenStack to build and manage their cloud infrastructures. For example, CIB Fintech Company used OpenStack to build the first and most extensive cloud infrastructure for the Chinese financial industry.
- Government institutions. Various levels of government use OpenStack to meet their cloud computing needs. For example, the French government's interior ministry has been using OpenStack private clouds to govern the country.
- Retail, transportation and healthcare industries. OpenStack is widely used in a variety of industries, including retail, transportation and healthcare. For example, Target, a major retailer in the U.S., tailors elements of OpenStack to accelerate the retrieval of updates and the backporting of fixes.
- Research organizations. Research organizations, such as the European Organization for Nuclear Research, also known as CERN, use OpenStack to support their scientific pursuits.
- Academic institutions. Academic institutions use OpenStack to meet their demands for research, education and cloud infrastructure. For example, the University of Hawaii and University of Cambridge use OpenStack to manage their cloud projects.
What are the different OpenStack components?
The OpenStack cloud platform is a combination of software components. These components are shaped by open source contributions from the developer community, and OpenStack adopters can choose to deploy some or all of these components as business needs dictate.
Figure 1 shows all OpenStack components, as of May 2023.
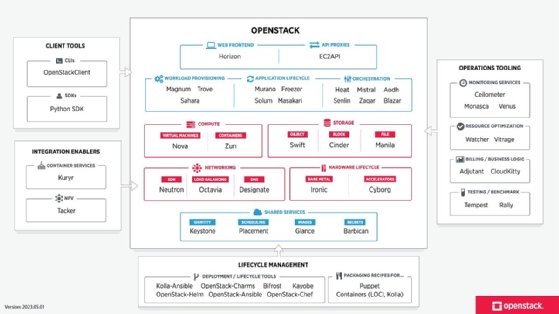
OpenStack setups vary but typically start with a handful of central components, including the following:
- Nova. This service manages compute resources and provides VM instances.
- Glance. This service handles the retrieval and management of VM images.
- Neutron. This project provides networking services, such as network administration and IP address management for VM network machines.
- Cinder. This service manages block storage devices and lets users attach and detach volumes from VMs.
- Swift. This software provides object storage for scalable and distributed storage needs, which is suitable for storing large volumes of unstructured data.
- Keystone. This component provides identification and authentication for OpenStack users and services.
- Placement. This OpenStack service lets organizations efficiently manage resources and allocate cloud resources by providing services with an HTTP API for tracking resource inventories and usages.
- Horizon. This service provides a web-based dashboard for users and admins to manage and monitor their OpenStack resources.
- Trove. This service facilitates the provisioning and management of databases for users by controlling database instances in an OpenStack environment.
- Ceilometer. This component is responsible for the billing and metering of the rendered services. It's also used to generate alarms when a certain threshold is exceeded.
- Heat. This service provides cloud resource autoscaling in conjunction with on-demand service provisioning. It functions in tandem with Ceilometer.
What are the pros and cons of OpenStack?
OpenStack infrastructure offers organizations the following benefits:
- Affordable. OpenStack is available freely as open source software released under the Apache 2.0 license. This means there's no upfront cost to acquire and use OpenStack.
- Reliable. With almost a decade of development and use, OpenStack provides a comprehensive, proven, production-ready and modular platform upon which an enterprise can build and operate a private or public cloud. Its rich set of capabilities includes scalable storage, good performance and high data security, and it's broadly accepted across industries.
- Vendor-neutral. Because OpenStack is open source, some organizations consider it a way to avoid vendor lock-in with an overall platform, as well as its individual component functions.
- Scalable. Based on demand, OpenStack lets users easily scale their infrastructure resources up or down.
- Secure. With OpenStack, organizations can get more control over their cloud environment, including access privileges, security measures and security rules. This is useful for regulatory compliance and data protection.
But potential adopters must also consider some drawbacks, including the following:
- Complexity. Because of its size and scope, OpenStack requires an IT staff with significant knowledge to deploy the platform and make it work. In some cases, an organization might require additional staff or a consulting firm to deploy OpenStack, which adds time and cost.
- Lack of support. As open source software, OpenStack isn't owned or directed by any one vendor or team. This can make it difficult to obtain support for the technology beyond the open source community.
- Upgrading challenges. Upgrading to new versions of OpenStack can be complex and time-consuming, especially if admins want to avoid disruptions and data loss.
- Lack of consistency. The OpenStack component suite is always in flux as new components are added and others are deprecated.
- Performance issues. Due to its resource-intensive nature, OpenStack can cause performance concerns in large deployments. Additional hardware and resources might be required to ensure peak performance.
To reduce the complexity of an OpenStack deployment and to gain direct access to technical support, an organization can select an OpenStack distribution from a vendor. This is a version of the open source platform packaged with other components, such as an installation program and management tools. It often comes with technical support options.
Organizations have many OpenStack distributions to choose from, including Mirantis OpenStack for Kubernetes, Rackspace OpenStack Private Cloud and Red Hat OpenStack Platform.
OpenStack vs. other cloud platforms
When comparing OpenStack to other cloud platforms, such as CloudStack, OpenStack stands out for its powerful open source nature, integrated architecture, scalability and multihypervisor support. Designed to build and manage cloud computing platforms for both public and private clouds, OpenStack's flexibility and extensive community support make it a popular choice among organizations.
However, even simple clouds are complex and require extensive automation, orchestration and management to operate. This means there are few direct alternatives to OpenStack that are practical and proven and that can simplify or speed an enterprise's adoption of next-generation technology.
Alternatives to OpenStack include the following:
- Containers. Organizations with small, dynamic, container-based environments might balk at OpenStack's embrace of traditional VMs. They can instead opt for a pure container-based approach using a platform such as Kubernetes.
- Hybrid cloud stacks. The three major public cloud providers offer managed platforms for on-premises clouds, with a strong emphasis on hybrid cloud adoption. AWS Outposts, Azure Stack and Google Cloud Anthos all offer appliances that sit within a local data center to facilitate a range of services that mimic the providers' public services and capabilities.
- VMware vCloud. Given the vast enterprise investments in virtualization technology, it's natural to consider building a private cloud based on VMware's vCloud Suite. VMware has partnerships with cloud providers, notably AWS, to support such hybrid cloud projects. However, VMware software is proprietary and requires licensing, and it might offer fewer capabilities and less flexibility than an open source platform, such as OpenStack.
- Public clouds only. Many organizations decide that the breadth and reliability of public cloud services fulfill their requirements, thereby avoiding the need to invest in a private cloud infrastructure.
How to get started with OpenStack
OpenStack adoption is a process. There are potentially dozens of components to understand, install and employ. Organizations that want to build a private cloud based on OpenStack need time, financial investment and support from upper management.
The following steps are usually involved when getting started with OpenStack:
- Evaluation. OpenStack adoption typically starts with a technology evaluation -- a test drive to see what an OpenStack setup looks like and how it operates. OpenStack Public Cloud Passport offers trial programs from several OpenStack public cloud providers. Organizations that prefer to install and run OpenStack locally for a hands-on examination can use the DevStack distribution, which focuses on the dashboard and OpenStack administration or user interactions and can be installed on a single computer.
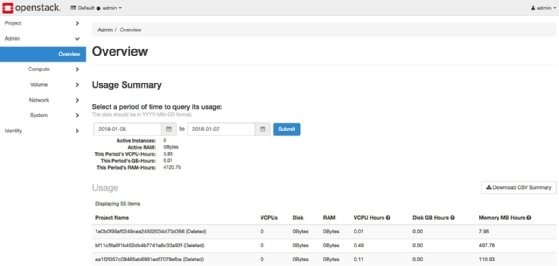
![OpenStack Horizon dashboard]()
Figure 2. Screenshot of the OpenStack Horizon dashboard, from which IT admins can view usage and manage instances, volumes, networking and other functions. - Preparation. Once an organization chooses to adopt OpenStack, it must prepare to address the following three elements:
- Education. Learn more about OpenStack components, how they operate and how they're used.
- Support. Identify and engage with OpenStack support services, from simply finding online communities to identifying competent OpenStack employees and third-party contractors.
- Infrastructure. Identify the hardware infrastructure to initially deploy OpenStack, which might require procurement and installation.
- Deployment. Organizations should consider starting with limited, proof-of-concept OpenStack projects. For example, OpenStack Compute Starter Kit focuses on the Nova compute service, Glance image services, Keystone identity management service, Neutron networking project and Placement service for tracking resource usage.
- Testing. Following the deployment of OpenStack, comprehensive testing should be done to ensure that all services are functioning correctly. Organizations should test a range of scenarios, such as launching instances, creating networks and gaining access to resources, to validate the functionality of the OpenStack deployment.
- Monitoring and maintenance. To keep an eye on the functionality and overall health of the OpenStack deployment, organizations should use tools for logging and monitoring. They should also apply patches and upgrades as needed to the OpenStack environment as part of routine maintenance and updates.
- Expansion. As an organization gains expertise in the OpenStack environment, it might want to add components. Although it's unlikely that every business use case needs every available component, organizations can select components, such as monitoring or billing, that fit their specific business goals.
OpenStack releases
OpenStack versions are released in the spring and fall of each year. These releases follow an alphabetical naming scheme, starting with the initial Austin release in 2010.
OpenStack releases 2010-2019
- The original OpenStack releases -- Austin, Bexar and Cactus -- are no longer available. Releases between 2012 and 2016, including Diablo, Essex, Folsom, Grizzly, Havana, Icehouse, Juno, Kilo, Liberty, Mitaka and Newton, are also no longer available and are at end-of-life status.
- OpenStack releases from 2017 to 2019 are now in extended maintenance status. These include Ocata, Pike, Queens, Rocky, Stein and Train.
OpenStack releases 2020-2021
- OpenStack releases in 2020, Ussuri and Victoria, are in extended maintenance mode and are actively maintained and supported by the community.
- The Wallaby OpenStack release arrived in April 2021 and is under extended maintenance. Notable improvements in Wallaby focus on role-based access control and integration with other open source projects, including Ceph distributed storage, Kubernetes container orchestration, and Prometheus monitoring and alerts.
- Xena was released in October 2021 and is under extended maintenance.
OpenStack releases 2022-2023
- OpenStack releases in 2022 include Yoga, which was released in March, and Zed, which was released in October. Both are being actively maintained.
- OpenStack releases in October 2023 include Antelope and Bobcat. Both are currently in maintained status.
Future OpenStack releases include Caracal, which has an anticipated release date of April 2024.
OpenStack Foundation
OpenStack was originally developed through a partnership between the National Aeronautics and Space Administration and Rackspace, a managed hosting and cloud computing service provider. In September 2012, the OpenStack Foundation was created as an independent nonprofit organization to oversee the OpenStack platform and community.
In October 2020, the OpenStack Foundation was relaunched as the Open Infrastructure Foundation (OpenInfra Foundation) with a mission to more broadly support other open source infrastructure communities and foster continued development around public, private and hybrid clouds. It's governed by a board of directors composed of many direct and indirect competitors, including IBM, Intel and VMware. Various OpenInfra Foundation projects involve artificial intelligence and machine learning, continuous integration/continuous delivery software development paradigms, container infrastructure and edge computing.
OpenStack platform providers
While comprehensive and capable, an OpenStack platform is difficult to deploy from scratch. The OpenStack market provides a variety of alternatives, including the following:
- Distributions. Organizations can choose prepackaged software that includes or supports OpenStack. Examples include Debian and Red Hat OpenStack Platform.
- Appliances. These combine OpenStack software with vendors' selected hardware to accelerate deployment. Examples include Hyper-C and Ericsson CEE9.
- Managed private cloud. Third-party organizations can support and help with local OpenStack deployment and operation. Examples include Cleura Private Cloud and Rackspace OpenStack Private Cloud.
- Hosted private cloud. Some organizations can't deploy and manage a private cloud on-site and instead rely on third-party providers to handle the hardware and management of OpenStack-based private clouds. Examples include Canonical Managed OpenStack and Rackspace OpenStack Private Cloud.
- Public cloud. Various public cloud providers offer services based on OpenStack technology, including Elastx OpenStack IaaS and Vexxhost Public Cloud.
Cloud computing has gained immense recognition in recent years. Delve into the top frequently asked questions about cloud computing to ensure informed decision-making when transitioning to the cloud.