Object vs. block vs. file storage: Which is best for cloud apps?
Object, file and block storage often vie for the hearts and minds of cloud app users. Making the right choice can have a profound effect on app performance, reliability and cost.

Block, file and object storage have significant differences and similarities. Over the years, those differences have narrowed while the similarities have grown, making choosing the most appropriate storage for cloud applications even more difficult.
Choosing storage begins by determining the needs and requirements of cloud applications, such as storage access via:
- Block: NVMe, NVMe-oF, iSCSI, Fibre Channel
- File: NFS, SMB
- Parallel file: Lustre, Spectrum Scale, Panasas, WekaIO, BeeGFS
- Object: S3 (RESTful API)
If the application can only access storage through a specific protocol and the application owner can't spend the time and resources to modify the application, the storage decision is made by default.
If this isn't the case, other requirements that influence the decision include stateful container persistent storage -- not a given for all systems -- data protection, business continuity, disaster recovery and security. Be sure to get application owners to sign off on the requirements before moving forward.
The second step to choosing the most appropriate storage for cloud applications requires a grasp of what they are, what they do, what they don't, best use cases for each and how object vs. block vs. file storage compare. Comprehension and knowledge depth reduce the risk of making a less than ideal choice for the organization's specific needs.
What is block storage?
Block storage is the default type for the storage media -- HDDs or SSDs -- in servers and workstations. It's also found in DAS, SAN and Remote Direct Memory Access (RDMA) storage using NVMe-oF protocols.
It's called block because data is broken up into and stored as blocks. These blocks are physically distributed across the storage media for optimal efficiency. Every block is given a unique identifier that enables the data to be reconstituted for reads.
Advantages of block storage
Performance is the biggest advantage of block storage for cloud applications. Specifically, latency. Latency is extremely important when it comes to application transaction response time. Lower latency translates into faster response times and more IOPS.
Block storage is also relatively simple. Server file systems write to it natively. Cloud applications typically use cloud block storage when they need fast reads or writes. Because block storage decouples application data from the application, it enables that data to be spread across multiple drives and volumes. That accelerates data retrieval.
Disadvantages of block storage
Block storage has no metadata. That limits its flexibility. There is no search capability or built-in data analytics. Although several block storage systems promote their analytics, these are primarily storage and drive analytics, not data analytics.
Cloud block storage frequently has severe scalability limitations. Cloud applications are limited to the number of drives accessible.
Block storage use cases
Most common use cases for block storage are:
- Relational or transactional databases.
- Time series databases.
- Mission- and business-critical applications requiring very low latencies and response times. Examples include high-frequency trading, e-commerce such as Magento, online transaction procession, CRM and marketing automation.
- General storage for virtualized and bare-metal servers.
- Underlying storage media to file and object storage.
- Hypervisor file systems, which also tend to use block storage because of its distribution across multiple volumes.
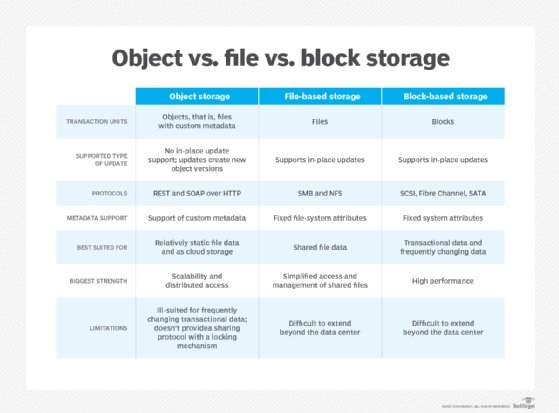
What is file storage?
File storage is organized similarly to the way people organize physical files in a filing cabinet. Files are systematically placed into folders and organized by naming conventions based on characteristics such as extensions, categories or applications. File systems are presented as a hierarchy of directories, subdirectories and files. Also, files are stored with limited metadata, such as file name, creation date, creator, file type, most recent change and last access.
Locating a file is done either manually or programmatically by working through the hierarchy. Users or cloud applications accessing a file simply require the path from directory to subdirectory to folder to file. It's generally easy to name, delete or otherwise manipulate files without any additional interface because the files are already organized in a hierarchical directory tree.
Searching for and locating files is relatively easy with a small number of files, but it can be extremely difficult as the number of files gets into the billions.
One variation of file storage is parallel file storage. This type of file storage system is architected for massive concurrent reads and, to a lesser extent, massive concurrent writes. Parallel file storage is most common with Data Direct Networks, IBM Spectrum Scale, open source Lustre, open source BeeGFS, Panasas and WekaIO. The use cases are narrow but growing.
Advantages of file storage
Simplicity is commonly considered the biggest advantage of file storage. That advantage is further realized in the cloud through expanded file sharing and collaboration.
Many applications have been written and optimized for file storage. Ubiquitous hypervisors from vendors such as VMware have NFS built in. Several relational databases such as Oracle and Microsoft SQL Server natively work with file storage, as do popular open source databases such as MySQL, MariaDB, PerconaDB and PostgreSQL. Also, most schema optional databases such as Casandra and MongoDB work natively with file storage.
There is another advantage that comes from third-party file storage running in the public cloud: software implementations from storage vendors such as Dell EMC, Pure Storage, Rozo Systems, StorOne, WekaIO and Zadara Storage. These pay-as-you-go (PAYG) cloud subscription offerings enable shared file storage for cloud applications, which reduces cost by eliminating orphaned storage. Expensive SSD or NVMe SSDs can be shared among multiple applications.
Disadvantages of file storage
Cost is the most notable disadvantage of file storage in the cloud. File storage in the cloud is often three to four times more expensive than block storage and an order of magnitude more expensive than object storage in the cloud.
Performance is another issue. File storage requires an overhead layer of software in front of block storage media. That adds latency and reduces response time, IOPS and throughput. However, several file storage systems have significantly reduced that overhead latency, making it much less of a problem. They've done this by making their file storage software much more efficient (StorOne), or by optimizing it for flash (Pavilion Data Systems, Pure Storage, Vast Data), by adding processing power (Pavilion Data) or by using low latency RDMA NFS (several).
Perhaps the disadvantage most asserted for file storage systems is limited scalability. File storage systems can bog down as the number of files escalate into the hundreds of millions to billions. This is an outdated perception that doesn't apply to many of the latest file storage systems. More recent file storage systems – Ctera Networks, Dell EMC, Nasuni, Panzura, Pavilion Data, Pure Storage, Qumulo, Vast Data and WekaIO -- have overcome this historical file storage scalability bottleneck by implementing a scale-out architecture and/or global namespace.
File storage use cases
Most common file storage use cases are:
- AI-machine learning
- AI-deep machine learning
- Analytics of all kinds
- Health records
- Video streaming
- Audio streaming
- Multimedia in general
- Office applications
- Target storage for backup
- Target storage for archive
- File sharing and workflow collaboration
Less common, but still important, file storage use cases include:
- High-performance computing cluster applications utilizing parallel file storage
- Geographically distributed global namespace (sharing/collaboration)
- Ctera, Nasuni, Panzura
- VMware ESX and vSphere
- Relational databases
- Schema optional databases
What is object storage?
Object storage organizes unstructured data in a way that is very efficient while being unintuitive to people. There is no hierarchy -- it's all about the individual objects. It's a shared-nothing architecture that enables, theoretically, unlimited scalability. Files are stored as objects in different locations, and each object has a unique identifier with considerable amounts of metadata. The metadata amount is variable -- and significantly greater than file metadata -- ranging in size from kilobytes to gigabytes.
Object storage metadata includes the metadata typically found in file systems, while commonly including a summary of the content in the file, keywords, key points, comments, locations of associated objects, data protection policies, security, access and geographic locations.
That enhanced metadata enables object storage to protect, manage, manipulate and keep objects on a much finer level of granularity than either block or file. A general example of this is the ability of object storage to increase data durability with the use of erasure codes.
Erasure codes break a file into multiple objects on different storage drives, storage/server nodes and even geographic locations. Erasure codes deliver data resilience from multiple concurrent drive and/or storage node failures. This is higher resilience than RAID or even triple-parity RAID.
Locating data represented by multiple objects is done via the object's unique identifier and its metadata. There is no hierarchy to scan or crawl. Finer granularity means many functions can be provided on a per-object basis. When data protection, replication, search, mining, moving and managing are more granular -- as it is in object stores -- it also becomes faster and more efficient. This is increasingly noticeable as the number of files grows to the billions or trillions.
Advantages of object storage
The biggest advantage of object storage is low cost. This is a primary reason that organizations select it for cloud applications.
Massive scalability is the second biggest advantage. That scalability is the direct result of object storage's shared-nothing architecture and flat structure. The use of globally unique identifiers versus the hierarchies of file storage or block storage facilitates that scalability. Object stores have proven growth into exabytes of data and have the potential to grow to zettabyte or even yottabyte scale.
Unrestricted metadata provides additional advantages. Storage administrators have flexibility in how they enable data preservation, data retention, data movement from higher value nodes using flash SSDs to lower value nodes using HDDs, and data deletions or expirations.
Another advantage is data resilience against hardware failure because of erasure coding. Object storage can be programed to protect against large numbers of drive and/or storage node failures. Drives aren't rebuilt as is done with RAID, but the data is, and it's rebuilt quickly across multiple drives.
Object storage has become the principal storage for the largest public cloud providers including AWS, Microsoft, Oracle, Google, Alibaba and IBM because of these benefits.
Disadvantages of object storage
Erasure coding is great for data resilience, but it adds significant latency for reads and writes. Erasure coding is CPU- and memory-intensive, slowing response times noticeably. Therefore, object storage is rarely used beyond secondary or tertiary storage. Some vendors have attempted to mitigate this latency issue with implementations that focus on flash SSDs. These are faster but still have latencies higher than block or file storage with SSDs.
Erasure coding also doesn't protect against data corruption, human errors or malware/ransomware. Object storage, in general, doesn't provide snapshots, a staple for block and file storage that does provide that level of protection.
Many object storage systems -- file and block storage systems, too -- can provide retention-based immutable or write-once, read-many storage containers or buckets. This prevents the data from being altered in any manner during the retention period. This is an important capability in the current environment of ransomware and privacy laws. However, most of these systems generally don't scan, detect or isolate malware/ransomware in the data stored in that immutable storage.
Although several object stores (DataCore Caringo, IBM Red Hat Ceph, Scality Ring) have a built-in NAS front end or physical NAS gateway, they can't match the response time performance of native NAS systems. Both file and object storage often have a block iSCSI gateway function. Once again, the NAS variation is usually -- although, not always -- more performant than the object storage equivalent. To take full advantage of an object store, the application or server file system must use the RESTful API. The defacto standard RESTful API is currently S3. As AWS popularity has grown, so has the number of applications using the S3 API. This isn't as much of a disadvantage as it used to be, but it still lags considerably behind file storage applications.
File systems, on the other hand, are accessed through standard NFS, SMB, parallel NFS, RDMA NFS or even Hadoop Distributed File System protocols, as well as IBM Spectrum Scale (formerly Global File Sharing System), Lustre, Panasas and WekaIO.
Object storage use cases
Most common file storage use cases are:
- Target storage for backups.
- Target storage for archives or vaults.
- File sharing and collaboration using file sync-and-share applications as the central repository.
- Health records.
- Video streaming.
- Audio streaming.
- Multimedia in general.
- AI, machine learning and deep machine learning, especially with very large data sets.
- Geographically distributed global namespace edge filers (Ctera, Nasuni, Panzura) using object storage as the centralized data lake.
- Data lake for large scale analytics such as data warehouses.
- Snowflake runs its data warehouse cloud service on top of AWS S3 object storage.
Storage selection cost considerations
The final step to choosing the most appropriate storage for cloud applications is calculating TCO. It's not simply the purchase or subscription price. It also includes supporting infrastructure costs such as rack space, switches, cables, conduit, transceivers, power, cooling, uninterruptible power supply, WAN (if required), training, technology refresh, planned downtime, unplanned downtime and time.
Time spent training, managing, operating, provisioning, troubleshooting and upgrading are major costs and are too often not taken into consideration. And that doesn't include how cloud application performance affects other costs, such as employee productivity, revenues, products' time-to-market, analytics and AI time-to-actionable insights.
Caveats to storage type differentiation and choosing
Storage continues to evolve. Just as there are pure play storage systems for block, file and object storage, there are also hybrid storage systems. These systems provide block, file, parallel file and object; or block, file and object; or just file and object in a single storage system. Public cloud service providers also tend to provide block, file and object in their storage services.
Some converged storage systems emphasize one storage type while compromising the others. In addition, some have limited scalability. Make sure the storage system chosen supports current cloud application requirements and will continue to do so in the foreseeable future.
Also, don't assume cloud application storage is limited to the storage provided by the public cloud service provider. Many storage vendors have "cloud-adjacent" services where they can put their systems in colocation with or very close to the public cloud service provider; they link via a high-performance 10 Gbps pipe. In addition, most storage vendors have PAYG elastic subscription programs that mirror cloud storage fees but with more performance and storage services.







