
Fotolia
Object storage systems: Benefits, alternatives and use cases
Along with proving itself a reliable option, object storage has stood the test of time. It can tackle unstructured data and the cloud, and it's overcoming performance challenges.

No one need argue the merits of using object storage systems. They have become a storage staple over the years, facing off against alternatives and adapting as needs and technologies change. Object storage is scalable and it deals with metadata on a granular level. It makes unstructured data less daunting, which is critical as the volume of data that organizations store and work with continues to grow.
Object storage has changed with the times and has the capacity to meet performance and storage demands of the modern data center. Along with handling unstructured data, object storage works well with the cloud. Performance -- one of the drawbacks of object storage -- has improved with the addition of high-performance object storage.
While we may be past asking what object storage is, there are still plenty of questions surrounding the technology, especially as demands change. Below, we answer four frequently asked object storage questions.
How does object storage match up with alternatives?
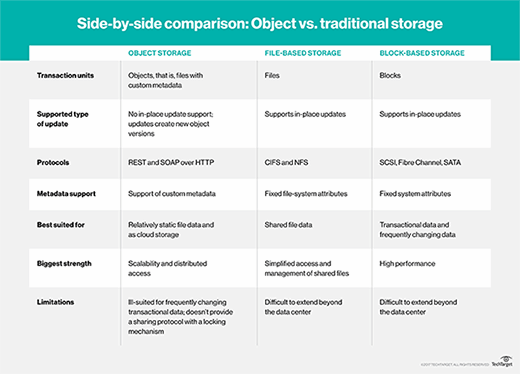
If you're familiar with object storage, you likely know its main competition: file and block storage. While object storage is newer than file and block, it's no longer a novel technology. Block and file storage have had more time to prove themselves, but object storage has made up for lost time. The growth of unstructured data is and will continue to be a major concern for many organizations, and object storage is up to the task of providing unstructured data storage.
Data analytics provides valuable insight for any company, and the way object storage systems classify metadata makes this easier than sifting through file and block storage. Modeled after paper documents and folders arranged in filing cabinets, there is a structure to file storage. However, given the volume of data that companies are storing, finding one piece of information is tedious work.
Object storage also proves beneficial when dealing with cloud storage. Performance may be a concern, but object storage's benefits make it well suited to working with the cloud. Backup and archiving -- two areas where the cloud is frequently used -- are well suited to object storage systems.
Why is object storage important today?
A primary benefit of object storage is how well it manages unstructured data, which is critical for modern data storage. With the rise of AI, machine learning and IoT technology, organizations are creating unprecedented amounts of unstructured data. Along with the ability to manage unstructured data, object storage makes it easy to add capacity without buying more than is needed.
It also won't break the bank. Object storage prices are similar to tape storage, making it an accessible option that fits a smaller budget.
Object storage also uses replicas or erasure coding across multiple data centers, so it can be available in different regions without a significant change in performance. With so many organizations working remotely because of the COVID-19 pandemic, or simply working with remote data centers, this level of availability is critical.
What are common uses?
Data storage looks different today than it did when object storage was created in the 1990s, and while unstructured data and scalability are key strengths, it also has gained some new uses. Object storage systems give real-time access to data from multiple locations, making it an appealing option for organizations looking to provide access to hundreds of users in different locations.
As more companies implement data lakes, which aggregate data from different sources in different formats, object storage's use of metadata makes that process more manageable. Today, businesses are using data lakes for many tasks, including logs, application telemetry, financial transactions, online interactions and social media.
Machine learning, AI and big data analytics benefit from using object storage, as well as repositories for search engines.
What about performance?
Performance has been the No. 1 drawback of object storage compared with the alternatives. Object storage's granularity and ability to work across multiple data centers in different locations are bound to slow it down. However, high-performance object storage is changing that. The use of flash-based media, in particular, is improving object storage performance, but the latency caused by the amount of metadata often ends up undoing progress when it comes to performance.
Metadata is the reason object storage is so good at what it does, but it is also what holds object storage back. Large amounts of metadata managed and stored between nodes create bottlenecks and deal a major blow to performance in more complex workloads. Newer object storage systems have changed the way they handle metadata, distributing it on every node in a cluster instead of just a few controllers.
Such improvements mean that organizations don't always have to sacrifice performance to get the cost and scalability advantages of object storage. Because it provides lower costs and better scalability, depending on the workload, object storage just might be a good fit.





