Free DownloadData Storage Management: What is it and Why is it Important?
With this guide, explore what data storage management is, who needs it, advantages and challenges, key storage management software features, security and compliance concerns, implementation tips, and vendors and products.
High-performance object storage challenges in the modern data center
Object storage works well for long-term backup and archiving. See how high-performance capabilities are expanding it to high-scale, high-capacity workloads.
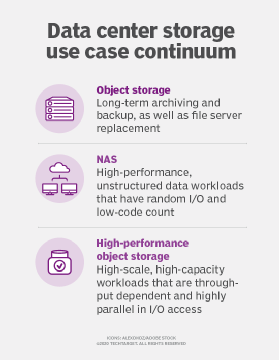
One of the most interesting aspects of object storage is its diversity of uses. While object storage is often used as an archive storage area, a destination for old data and a replacement for production file servers, in reality there are many ways it can be applied. As vendors begin to deliver performance-optimized object storage, the technology is ready for a whole new set of workloads.
High-performance object storage requires more than just switching from hard disk-based object storage systems to all-flash object storage. The move to all-flash media certainly helps, but object storage systems -- thanks largely to their rich metadata -- typically have too much latency to effectively take advantage of flash performance.
Another challenge to creating a high-performance object storage system is the scale-out nature of the infrastructure. To meet capacity demands, object storage adds nodes to a storage cluster. Each node's capacity is assimilated into the cluster, creating a storage pool. In a large scale-out cluster, dozens, if not hundreds, of nodes are common. The latency of aggregating and managing these nodes can be high.
The AI and deep learning object storage challenge
Large, unstructured data workloads, such as AI and machine and deep learning, are good examples of how object storage architecture can be a problem for high-performance workloads. On paper, these workloads should be ideal for object storage. They have millions, and possibly billions, of files. Storing all this data requires a lot of SSDs or HDDs and, consequently, many nodes. The processes are also throughput driven.
All these factors combined make AI and deep learning tailor-made for the high-node-count storage cluster typical of object storage. And most of the frameworks, such as TensorFlow, that drive AI and machine learning workloads, use the Amazon S3 protocol when communicating with storage. Most object storage systems are also S3-based, and S3 is itself highly parallelized. In theory, an object storage infrastructure should be able to meet the AI and machine or deep learning workload demands.
But this approach requires more than creating an all-flash object storage system. The system must be able to address the reality that there will likely be dozens, if not hundreds, of nodes and that metadata, as well as cluster management, also present challenges.
Coping with metadata challenges
metadata, which is data about data, is a challenge to high-performance object storage for two reasons. First, an object storage system requires more time to manage its rich metadata. Management is further complicated because most object storage vendors designate a select number of nodes in the cluster to manage and store the metadata. In workloads like AI and deep learning, the dedicated metadata controllers are often overwhelmed with metadata and become a bottleneck. As a result, flash drives and even hard disk drives can't perform to their full potential.
The second metadata challenge is cluster communications. Most scale-out NAS or block storage systems have a comparatively small node count. A six-node storage cluster is considered large in NAS and block use cases, but six nodes are considered just getting started in many object storage deployments. Internode communication becomes a massive issue, especially in use cases that don't involve archives where performance is a concern.
Creating a high-performance, at-scale object storage solution requires addressing metadata performance and cluster management issues.
Creating a high-performance, at-scale object storage solution requires addressing metadata performance and cluster management issues. Next-generation object stores distribute the metadata on every node in a cluster instead of just a few controllers. The distribution of metadata ensures every node has all the information it needs to respond to an I/O request.
Other high-performance object storage issues
Object storage systems must also address issues with internode networking. The distribution of metadata helps here because it lowers the amount of east-west traffic. Vendors have to optimize their internode networking, so it doesn't bottleneck performance. More than likely, they must optimize network communication to minimize the frequency of transmissions.
Another area where optimization is needed is protocol emulation. For example, most object storage systems support NFS. NFS support is critical because many IoT devices aren't native S3 and use NFS. The challenge is that many object storage systems bolt on a separate component that translates between NFS and S3 instead of running NFS natively from within their software. The overhead of the translation is significant, and it shows in high-performance situations.
Native integration of NFS within object storage code enables higher performance and simultaneous access to the same data. The concurrent access means that an IoT device could send the data via NFS to an object store volume and, at the same time, an AI or deep learning framework can process it via an S3 object without it being copied or moved.
Where NAS fits in
NAS systems still have a role to play in the data center. They now sit in between two extremes. Object storage is ideal for long-term archives and backups, although high-capacity NAS can still compete in the backup storage market. Object storage also is suitable as a file server replacement for workloads such as user home directories where performance is less of an issue.
High-performance object storage is ideal for high-scale workloads that require dozens or hundreds of nodes and capacities in the dozens of petabytes. These workloads also must be throughput-dependent and highly parallel in I/O access. In between these two extremes are high-performance, unstructured data workloads that are random I/O in nature and where node count is in the low teens. In these use cases, NAS may still be the better choice.
Next Steps
Nine reasons object-level storage adoption has increased