Advantages of using an object storage system
Learn the advantages of implementing an object storage system in your data storage environment.

What you will learn: Object storage systems are becoming a viable alternative to scale-out network-attached storage (scale-out NAS) because of their unlimited scalability, lower emphasis on processing and high-capacity networks, access via Internet protocols rather than storage commands, custom metadata and off-the-shelf component-compatibility. Where we used to see a file- or block-based system, we now see an object storage system, and this is especially true when talking about public and private cloud storage. In this expert feature, Jacob N. Gsoedl provides an in-depth explanation of how object-based storage systems work and how they've become the fundamental building blocks of a cloud storage infrastructure.
Object storage vs. traditional storage
With plenty of block- and file-based storage systems to choose from, the obvious question is why do we need another storage technology? Block and file are both mature and proven, so it may seem as if they could be enhanced to meet the needs of an increasingly distributed and cloud-enabled computing ecosystem.
With block-based storage, blocks on disks are accessed via low-level storage protocols, such as SCSI commands, with little overhead and no additional abstraction layers. It's the fastest way to access data on disks, and all higher level tasks such as multiuser access, sharing, locking and security are usually deferred to operating systems. In other words, block-based storage takes care of all the low-level plumbing but depends on higher level apps for everything else. Every object storage system has a block-based storage node, with the object storage software stack providing all other features.
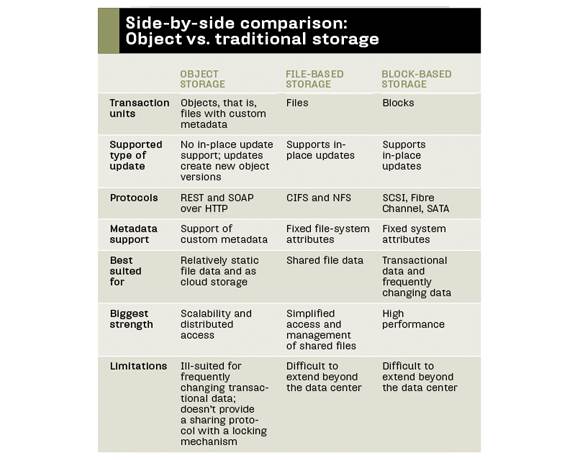
While block-based storage could be considered complementary to object storage, file-based storage might be a direct competitor. The key attribute of scalability is supported by scale-out NAS systems that, similar to object storage, scale horizontally by adding nodes. But because they're based on hierarchical file structures with a limited namespace, they're more restricted than the nearly infinitely scalable flat structure of pure object storage that's only limited by the number of bits of the object ID. Although more limited, scale-out NAS systems have many of the characteristics of object storage, and vendors are quickly adding missing features such as representational state transfer (REST) protocol support so they can classify their scale-out NAS systems as object storage. "With HP Ibrix X9000 Storage and its support of WebDAV, REST, in addition to CIFS, NFS and massive scalability, we're a clear leader in the object storage space," claimed Patrick Osborne, senior product manager in Hewlett-Packard (HP) Co.'s Storage Division.
Defining object storage
Clearly, object storage means different things to different people, so it lacks a single recognized definition. To analyze to what degree a storage system is object storage, one has to look at the attributes that are either required or "nice to have."
Objects. Rather than managing blocks or files, a pure object storage system manages objects. More precisely, all contemporary object storage systems manage files as objects. Objects are addressed via a unique identifier, just as files in file-based storage systems are addressed via file path. Objects are stored in a flat address space, which eliminates the complexity and scalability challenges of the hierarchical file systems used by file-based storage.
Metadata. Objects consist of metadata, which provides contextual information about the data in the object, and the payload or actual data. In file-based storage systems, metadata is limited to file attributes; metadata in pure object storage systems can be enriched with any number of custom attributes. To do that with a file-based system, you need an application (with a database) to handle any additional information related to files. With custom metadata you can store all information related to a file (object) in the object itself. "Custom metadata allows building rich, self-contained file objects that can be stored away in the object store, enabling building massive unstructured data stores with reduced administration overhead," said Terri McClure, a senior analyst at Enterprise Strategy Group (ESG) in Milford, Mass.
Fixed objects. Pure object storage represents a repository of fixed content; that means objects can be created, deleted and read, but they can't be updated in place. Instead, objects are updated by creating new object versions. As a result, the challenges of locking and multiuser access -- the bane of file-based systems -- simply don't exist with object storage. "If multiple users update the same file [object] concurrently, the object storage system will simply write different versions of the file," said Tim Russell, vice president of the data lifecycle ecosystem group at NetApp Inc. The compromise of not having to support in-place updates makes object storage a good fit as distributed storage and for distributed access.
Redundancy. Object storage accomplishes redundancy and high availability by storing copies of the same object on multiple nodes. When an object is created, it's created on one node and subsequently copied to one or more additional nodes, depending on the policies in place. The nodes can be within the same data center or geographically dispersed. The lack of in-place update support enables multinode-copy object redundancy with very little complexity. For traditional storage systems, keeping copied (replicated) files and blocks in-sync across multiple instances is a tremendous challenge; it's very complex and can only be done with a set of very strict restrictions, such as within defined latency constraints.
Protocol support. Traditional block- and file-based protocols work well within the data center where performance is good and latency isn't an issue. But they're not appropriate for geographically distributed access and the cloud where latency is unpredictable. Furthermore, traditional file system protocols (CIFS and NFS) communicate on TCP ports that are available on internal networks, but rarely exposed to the Internet. Conversely, object storage is usually accessed through a REST API over HTTP. Commands sent over HTTP to object storage are simple: put to create an object, get to read an object, delete to purge an object and list to list objects.
Application support and integration. The lack of traditional data storage protocol support and reliance on a REST API requires integration efforts for object storage to become accessible. Besides custom application integration, some commercial applications, especially for backup and archiving, have added object storage integration support, primarily linking to Amazon S3 cloud storage. Since the industry is still struggling to agree on standards, widespread object storage integration is still sparse. Object storage gateways, usually called cloud storage gateways, provide another way to communicate with object storage. Located between traditional and object storage, they shuffle data back and forth between the two, usually via predefined policies.
Cloud features. Because cloud storage and Web 2.0 applications are key targets of object storage, features related to shared access over the Internet are relevant. Multi-tenancy and the ability to securely segregate different users' data are must-haves for an object storage product to be used beyond the enterprise. Security is more than encryption, and should include provisions to control access to tenants, namespaces and objects. Service-level agreement (SLA) management and the ability to support multiple service levels are important for the cloud use. A policy engine that helps enforce SLAs, such as the number of object instances and where each instance should be stored, is an instrumental facility any object storage product should provide. Furthermore, usage metering and automated tracking of charges are indispensable for cloud use.

Use case. Pure object storage is inadequate for transactional data that changes frequently, such as databases. It's also not designed to replace NAS to access shared files because it doesn't have the locking and file-sharing facilities that ensure the single "truth" of a file; instead, object storage offers multiple, possibly incongruent versions of a file. Object storage works well as a tremendously scalable data store for unstructured data that's updated infrequently, either as an additional storage tier beyond transactional storage tiers for inactive data or as archival storage. In the cloud space, it's well suited for file content, especially images and videos. "Today, object storage is good for post-process-type data as found in the media, entertainment and health care industries, as well as for archival," said Jeff Lundberg, senior product marketing manager at Hitachi Data Systems (HDS). "But as performance increases and features mature, it can not only support cloud storage but will enable distributed IT environments."
Varied approaches to object storage
Object-based storage can be categorized into three groups:
Content-addressed storage (CAS): Under the hood, CAS stores files as objects with custom metadata and the files are accessed via numeric object identifiers. Architected for the disk-based archival space with strong compliance features, CAS systems are usually deployed within the data center, so they don't need cloud features, such as distributed access over the Internet and multi-tenancy. EMC Corp. has dominated the CAS space with Centera, with others like Caringo Inc. competing in the enterprise market. To turn their wares into cloud storage systems, CAS vendors can enhance their platforms with cloud-relevant features or create a new object storage platform. EMC took the latter route for Atmos, its cloud storage platform; Caringo built out its existing CAS system, now called the Caringo Object Storage Platform. Caringo has supported multi-tenancy and objects up to 1 terabyte in size since the release of version 5 of the object storage platform.
"In the second quarter of 2012, we'll introduce Cloud Scalar, which will extend our cloud storage platform with a RESTful interface, metering, enhanced access control and quotas, and a Web-based portal for administrative users," said Adrian Herrera, Caringo's senior director of marketing. Dell Inc.'s DX Object Storage Platform is based on the Caringo product. "Although the DX Object Storage Platform is from Caringo, we're adding value through integration and features like Ocarina deduplication," said Brandon Canaday, formerly with Dell and now vice president of strategic accounts for Caringo.
Second-generation object storage systems: Most other object storage players have developed their object storage software from scratch. Architected to work with inexpensive x86-based nodes, each storage node provides both compute and storage resources, and scales linearly in capacity and performance by simply adding nodes. The object storage software is typically hardware agnostic and consists of loosely coupled services: a presentation layer that handles interfacing to clients via HTTP protocols (REST or SOAP) and, optionally, traditional file-system protocols; a metadata management layer that manages where data objects are stored and how they're protected and distributed on storage nodes; and a storage target layer that interfaces with storage nodes.
EMC sells its Atmos object storage system as a virtual appliance, as software-only and as software with commodity servers and JBODS. "The key point of Atmos is the fact that each additional node adds capacity, compute and network resources, and you can literally add them infinitely," said Mike Feinberg, senior vice president of EMC's cloud infrastructure group.
In 2010, NetApp acquired Bycast, a developer of object-based storage software, and the technology is now the basis of NetApp StorageGrid. NetApp combines the StorageGrid software with NetApp E-Series storage systems to offer an object storage offering. "StorageGrid is in the same category as Atmos with several key benefits, such as RAID protection in the E-Series storage nodes to provide local redundancy in addition to multiple copies for DR," NetApp's Russell said.
Amplidata claims its AmpliStor product combines durability, scalability and high performance in the object storage product. "With a combination of our proprietary BitSpread technology, a codec that replaces RAID controllers to enable data durability beyond ten 9s, and high-performance nodes that can leverage solid-state disks for caching, AmpliStor is able to deliver 720 MBps throughput per controller," said Paul Speciale, Amplidata's vice president of products.
The Hitachi Content Platform (HCP) combines object storage software with HDS storage to deliver a state-of-the-art object storage solution that's well integrated with both the Hitachi NAS Platform (formerly BlueArc) and other HDS storage systems.
Cloud-enabled scale-out NAS: Even though they're not based on object storage architectures, their ability to scale horizontally by adding nodes allows scale-out NAS vendors to compete in the object storage space. Similar to CAS system vendors, scale-out NAS vendors are adding object storage features, such as HTTP protocol support. Because scale-out NAS systems are network-attached storage with an object storage mantle, it gives them an advantage over pure object storage products in internal cloud deployments.
Object lesson
The combination of unprecedented scalability and distributed access has enabled object storage to succeed in the cloud storage and Web 2.0 space. In corporate data centers, these systems are deployed as archival and file-aggregation storage tiers to supplement traditional data storage. Still, object storage represents a very small portion of the storage market that's dominated by traditional block- and file-based storage. The key for broader adoption is standardization and integration with apps, traditional storage systems and peer object storage systems.
This article originally appeared in Storage magazine.





