Computational storage: Go beyond computation offloading
Computational storage proponents include academia and the Storage Networking Industry Association. While there's behind-the-scenes work still to do, the tech could bring benefits.
By
Tong ZhangGuest Contributor
Published: 30 Sep 2021
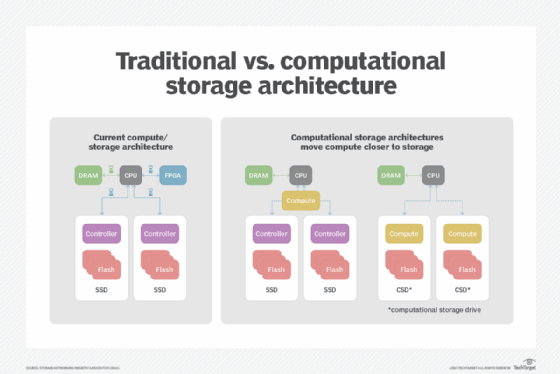
Computational storage has a simple rationale: move computational tasks closer to where data resides. By doing so, we improve system performance and efficiency. Because storage data is processed at all levels of the data center -- inside a server, across a network and, of course, in storage environments -- these efficiencies are highly sought after.
Part of the reason is that storage is not one monolithic entity. As a matter of fact, storage exists at many layers and has many different components. Some of these components have to do with the data itself -- storage, protection and transmission. Other components have to do with controlling systems of storage, setting up management planes, and even orchestrating how, where and when data is transmitted inside and outside different systems.
Think of it this way. Every technical offering has three basic components: compute, network and storage. In the past five years, however, each of these components has evolved to provide orders-of-magnitude better performance, reliability and utility. As a result, it's been possible to move these components into areas where they did not exist before. This is, in fact, the fundamental reason why we can have disaggregated products in the first place.
Benefits of computational storage
When we think of processing, then, we are now able to move beyond the notion of "fetching" data back to a host processor -- over a network, naturally -- in order to be processed. After all, not all data needs to be sent back and forth across the network. Instead, we can be more judicious and efficient about providing processing capability at the data location.
What does that mean in real terms? In part, it means:
fewer I/O transfers (the best I/O is the one that's never sent);
reduced possibility for errors in transmission, and reduced re-transmission across the network;
greater ability to process the data where it resides (also called in situ processing);
reduced CPU utilization on hosts;
improved performance thanks to parallelism for certain workloads; and
better scheduling of storage functionality not just as needed, but where needed (such as with compression, decompression, encryption and packet filtering).
Computational storage can help address these needs but does something even more important than just shoving compute and data together: it helps provide additional granularity of this work. From an architectural perspective, this means that instead of needing monolithic storage controllers to handle all of the storage functions, they can be placed in multiple places in the system. From a storage perspective, this is huge.
Over the past few years, more and more attention to the technology has come from areas such as academia, storage architecture and cloud providers. Take, for example, an entire issue on computational storage in a special edition from the Association for Computing Machinery.
It will be an evolutionary path for the entire ecosystem to embrace the new infrastructure in support of computational storage.
Academia has been a strong proponent of computational storage for a long time, proposing its use for artificial intelligence and machine learning, data reorganization and advanced applications of abstraction: "explicitly offloading application-level computational tasks from host CPUs to storage drives through the storage I/O stack," according to the book "Computer Architecture: A Quantitative Approach." To explicitly offload computation to storage drives through the I/O stack, one must address and effectively deliver ways to enhance the interfaces across the entire I/O hierarchy.
Explore potential for computational storage
Different computational storage devices may provide many different computational functions and capabilities. The ongoing standardization efforts of the Storage Networking Industry Association (SNIA) and NVM Express communities will undoubtedly play crucial roles in creating consistent and uniform methods of implementing computational storage.
After all, it will be an evolutionary path for the entire ecosystem to embrace the new infrastructure in support of computational storage, and at SNIA, more than 250 volunteer vendor members have been steadily and diligently working together to accelerate the process. (Of course, we sincerely welcome the participation from more parties!)
The work is starting to bear fruit. Many of the technical challenges involved have already been overcome, and strong collaboration promises to ensure consistency in the marketplace for both developers and end users. A steppingstone to extensive industry adoption of computational storage is native in-storage computation that is independent from or transparent to the storage I/O stack. This allows for adoption without the need for modifications to the storage stack, which takes more time to permeate the various OSes. There are several different options to realize native in-storage computation, more than can be illustrated in a single article.
Let's take a look at one such option: in-storage lossless data compression, which is carried out on each 4 KB data block inside the drive, transparently to the host. Lossless data involves a significant amount of random data access, leading to very high CPU/GPU cache miss rates. As a result, CPU/GPU-based lossless compression suffers from very low CPU/GPU hardware utilization efficiency and hence low speed performance. Therefore, native in-storage compression could transparently exploit runtime data compressibility to reduce the storage cost without consuming any host CPU/GPU cycles.
Another example is evident in the design of data management systems, such as relational databases, key-value stores and file systems. Here, the design is constrained by the fixed-size I/O of conventional storage drives. However, using computational storage relaxes the constraint imposed by the underlying storage drives by enabling variability and flexibility within that I/O block. In fact, by using native in-storage computation, this can be done without demanding any changes across the existing I/O stack.
In addition to these examples, native computational storage could include encryption, deduplication, virus detection, fault detection and tolerance, and many other functions. Moreover, one could run a complete Linux OS-based system inside computational storage drives, still being independent from the storage I/O stack in the host.
The efforts of SNIA and NVM Express are working to develop many different platforms for the market to unleash the full potential of computational storage by more conveniently enabling applications to offload computational tasks from host CPUs to storage devices.
More on SNIA's computational storage efforts
SNIA's computational storage work is led by the volunteer vendor members of the Computational Storage Technical Work Group (TWG). The TWG's most recent activities are the SNIA Computational Storage Architecture and Programming Model, v0.8 rev 0, and the SNIA Computational Storage API v0.5 rev 0, which are now out for public review.
The SNIA Computational Storage Special Interest Group accelerates the awareness and vendor-neutral education of computational storage concepts and influences industry adoption and implementation of the technical specifications and programming models.
About the author
Tong Zhang is a member of SNIA's Computational Storage Special Interest Group and Technical Work Group. He is a well-established researcher with significant contributions to the areas of data storage systems and VLSI signal processing. He is currently a professor at Rensselaer Polytechnic Institute. His current and past research spans a wide range of areas, including database, file system, solid-state and magnetic data storage devices and systems, digital signal processing and communication, error correction coding, VLSI architectures and computer architecture.
The Storage Networking Industry Association is a not-for-profit global organization, made up of member companies spanning the global storage market. SNIA's mission is to lead the storage industry worldwide in developing and promoting standards, technologies and educational services to empower organizations in the management of information. To this end, SNIA is uniquely committed to delivering standards, education and services that will propel open storage networking solutions into the broader market.