Growth of dark data shows need for better classification
Dark data causes all sorts of problems, but there are ways to mitigate it. However, customers continue to add storage as a bandage solution, because it's cheaper and simpler.
Dark data isn't just a data management issue. It causes problems in storage, backup, compliance and security, as the burden of unclassified data leads to added costs and liability.
Consulting and market research firm Gartner defines dark data as "information assets organizations collect, process and store during regular business activities, but generally fail to use for other purposes."
IT experts have pushed the dark side of the definition further, using the term to refer to poorly defined or uncategorized data. In an interview published on SearchSecurity, Splunk CTO Tim Tully defined dark data as unknown, unidentified or unused data. Enterprise data protection vendor Veritas similarly refers to it as data that is unclassified or untagged.
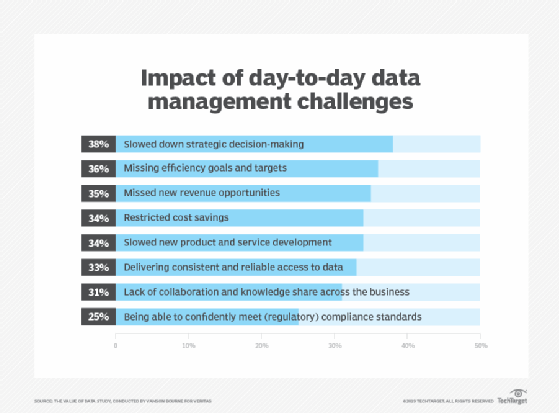
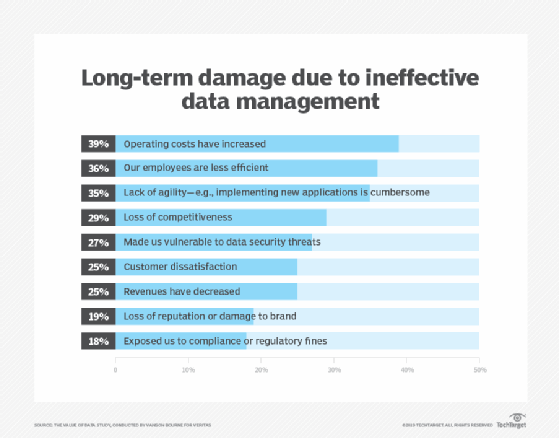
A recent study conducted by U.K.-based market research firm Vanson Bourne and commissioned by Veritas found 52% of data within organizations is considered dark data. The study polled 1,500 IT decision-makers across 15 countries on their data management challenges. Other takeaways include an average annual loss of $2 million due to inefficient data management and a productivity loss of two hours per day spent searching for relevant data.
The study highlighted how it's a data management issue, but the unknown nature of dark data causes many problems across multiple IT areas. For example, from a security standpoint, the dark data could contain server logs detailing where an attack is coming from.
Jyothi Swaroop, vice president of product and solutions at Veritas, based in Santa Clara, Calif., said another security concern is if a ransomware attack encrypts an organization's dark data.
"You're most worried when you don't know what's taken," Swaroop said, adding that if an organization knows exactly what it lost, it's easier to plan around or restore it.
Other problems lie in the maintenance of dark data. An organization can't tell if dark data is worth keeping, but they still pay to store and back it up just the same as properly identified, mission-critical data. From a compliance standpoint, dark data is a potential liability, because organizations can't know for sure if they've deleted every copy of something.
According to George Crump, founder of storage industry analyst firm Storage Switzerland, thanks to the proliferation of internet-of-things sensors, edge devices, cameras and other capture devices, the ability to collect data far outstrips the ability to categorize and process it.
"We're collecting too much data," Crump said. He added that most of this data is generated by systems and processes, such as log files.
Crump suggested several approaches to lowering or removing the bottleneck. One is to throw raw computing horsepower at the data analysis and classification process. Another is to be judicious about how frequently data is captured. The goal is to determine as quickly as possible whether data is worth keeping as its being ingested, which would stop the buildup of dark data.
To deal with an existing reservoir of dark data, analytics tools would need to be deployed to crawl through the data and retroactively classify it. Swaroop suggested the best way to prevent dark data is by building an intelligent, integrated data management system that provides visibility on the data from its moment of creation to its retirement or deletion.
Ignoring the problem
Crump said, 20 years ago, data management was a necessity, because organizations couldn't build storage systems that were big enough to hold every piece of data collected. Since then, storage technology improved and became cheaper.
We're collecting too much data.
George CrumpFounder of Storage Switzerland
"You literally couldn't build a storage system big enough, but now we can," Crump said. "Instead of being efficient with our management, we're throwing more storage at the problem. We can keep it forever, but we're missing the ability to quickly analyze the data."
This has also led to a mindset of never deleting anything, as it costs so little to keep it forever. Palmaz Vineyard generates about 1 GB of environmental conditions data every hour to help inform the machine-learning-driven fermentation process of its wine. CEO Christian Gastón Palmaz said he keeps all of that data.
"There's something wrong about deleting something that you worked so hard to create. There's always a way to store it," Palmaz said. "Once it's gone, it's gone forever. And, for me, it should always exist."
Another challenge lies in getting organizations to adopt data management technology. It is often hard for IT administrators to get their higher-ups on board, said Christophe Bertrand, senior analyst at Enterprise Strategy Group, based in Milford, Mass.
"These solutions don't come up with enough visible ROI," Bertrand said, making them a tougher sell to business leaders. Fixing dark data isn't profitable in and of itself, but turning the data into something useful, such as using it for analytics or test/dev, may be the key to changing minds.
But organizations will continue to throw more storage at the dark data problem, because it's the simplest way out, Crump said. He said, in his experience in consulting with businesses that have this problem, they usually did not know of a better way to deal with it, nor do they have the time to research and implement a service. As long as the added complexity doesn't exceed the downsides of buying more storage, the practice will continue.
"If you're drowning, you don't have time to learn to swim," Crump said.