
cycreation - Fotolia
MapR Data Platform gets object tiering and S3 support
MapR Technologies adds policy-based tiering to its Data Platform to automatically move data across performance, capacity and archive storage on premises and in cloud.

MapR Technologies updated its Data Platform, adding support for Amazon's S3 application programming interface and automated tiering to cloud-based object storage.
MapR is known for its distribution of open source Apache Hadoop software. It contributes to related open source projects designed to handle advanced analytics for large data sets across computer clusters. The 6.1 release of the MapR Data Platform -- formerly MapR Converged Data Platform -- adds storage management features for artificial intelligence applications that require real-time analytics.
MapR Data Platform 6.1, scheduled to become generally available this quarter, features policy-based data placement across performance, capacity and archive tiers. It also added fast-ingest erasure coding for high-capacity storage on premises and in public clouds, an installer option to enable security by default and volume-based encryption of data at rest.
Providing real-time analytics for AI requires coordination between on-premises, cloud and edge storage, said Jack Norris, senior vice president of data and applications at MapR, which is based in Santa Clara, Calif.
"What we're seeing increasingly is that the time frame for AI is decreasing. It's not enough to understand what happened in the business. It's really, 'How do you impact the business as it's happening?'" Norris said.
MapR storage additions
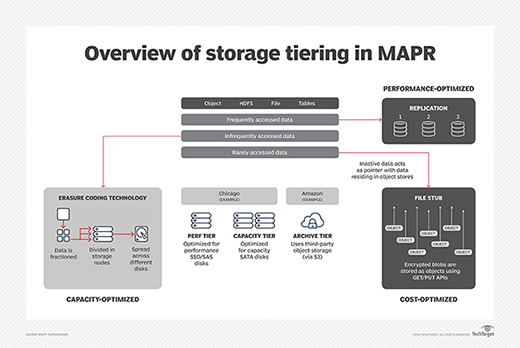
MapR Data Platform 6.1 expands storage features by adding policy-based tiering to automatically move data. It now supports a performance tier of SSDs or SAS HDDs; a capacity tier of high-density HDDs; and an archival tier of third-party, S3-compliant object storage. Customers supply the commodity hardware.
The storage management features follow the 2017 addition of MapR-XD software to MapR Converged Data Platform. MapR-XD is based on the company's distributed file system that was released in 2010. It includes a global namespace that can span on-premises and public cloud environments and support tiers of hot, warm and cold storage.
MapR writes all data to the performance tier and then determines the most appropriate way to store it, Norris said. Its tiering is independent of data format. Norris said the system could write NFS and read S3, or the reverse. For instance, MapR can place and store data as an object on one or more clouds and later pull back the data and restore it as a file transparently to the user.
"We do constant management of the data to account for node failure, disk failure, rebalancing of the cluster and eliminating hotspots," he said.
New MapR release adds file stubs
The MapR software handles data transformations between file and object formats in the background. With past releases, the MapR system had to go through an intermediate step to shift data between file- and object-based storage. With 6.1, MapR retains file stubs to represent data that the system has shifted to cloud-based object storage. The stub stores the location of the data.
"When you need to access that data, we're just pulling back an individual file," Norris said. "You don't want to pull back a whole directory or a whole volume. If you look at cost economics in the cloud, it's expensive, because you get charged by data movement."
The newly added support for the Amazon S3 API includes all core capabilities, such as the concept of buckets and access-control lists, Norris said.
MapR's new erasure coding spreads pieces of data across disks. Norris said the MapR erasure coding preserves snapshots and compression.
The MapR Data Platform is available in Enterprise Standard and Enterprise Premium editions. The Enterprise Standard offering includes MapR-XD, MapR-Document Database, MapR Event Data Streams and Apache Hadoop, Spark and Drill. The Enterprise Premium software tacks on options such as real-time data integration with MapR Change Data Capture, Orbit Cloud Suite extensions and the ability to add the Data Science Refinery toolkit.
Deviation from Hadoop
Carl Olofson, a data management software research vice president at IDC, said MapR's file system emulates the Hadoop Distributed File System, but its indexes and update-in-place capabilities set it apart. The challenge for MapR is the potential skepticism of having a "data lake solution that deviates so far from the Hadoop project code," Olofson said.
"The good news there is that even the other Hadoop vendors are no longer solely focused on Hadoop, so MapR may be on top of an emerging trend," he wrote.
Policy-based storage tiering is the key new capability in the MapR Data Platform 6.1, Olofson claimed. "As people move data lake technologies to the cloud, they are initially in sticker shock because of the storage costs associated with it," he said. "The MapR approach not only addresses that, but they say it does it automatically."
MapR's competition includes Cloudera, Hortonworks and various open source technologies, according to Mike Matchett, principal IT industry analyst at Small World Big Data. He noted concerns that MapR is "at heart a closed proprietary platform." But Matchett said he gives MapR an advantage over plain open source in terms of supporting mixed and now operational workloads.
"The theme for MapR in this release is to support big data AI and ML [machine learning] alongside and with business applications," Matchett wrote in an email.






