
Sikov - stock.adobe.com
How the key-value SSD promises to outperform block storage
Key-value SSDs show potential in performance and storage management, but how would they be implemented? What other advantages do they offer over block storage?

Interest has surged in key-value SSDs. But what makes them better than the original block storage that has been in place for years?
These drives can speed up system performance and simplify the software stack. As a result, the key-value SSD has clear uses but also some major pain points.
The fine print on keys and values
NoSQL databases tend to organize their data into keys and values. The data format fits this type of application well. In this format, a unique key points to data of an unknown size in storage, which is called the value. The value can be long or short. Similarly, the keys that point to the values in storage also have varied lengths. The only important restriction is that they must be unique.
The values in a key-value storage system range from as little as a single byte to tens of megabytes. They are expected to eventually grow to gigabytes of storage.
This type of format fits unstructured data well. As a NoSQL database manages data in a variety of formats, it takes advantage of this flexible approach to data management.
So why do we need a special SSD for this?
In most computers, a NoSQL database requires a layer to translate the key-value pairs that the database manages into the data format that most computers use. This data format consists of logical block addresses (LBAs), which are usually managed by a file system.
The file system manages the files on storage, and the block layer translates the file names into the blocks -- 512 bytes or 4,000 bytes -- on the physical block storage device. In this way, the file is mapped to available blocks on the disk. The host system manages a table of logical blocks to map the file into whatever space is available in the block storage device.
This system was all built around the block-based structure of the HDD, as shown in Figure 1.
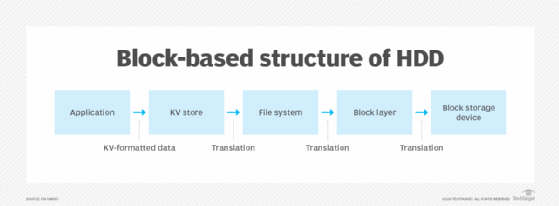
Another layer in Figure 1 is labeled KV store. This new function became necessary to match the NoSQL application's KV format to the format the file system expected. With this new layer, addresses are translated three times before they reach storage: first by the key-value store, next by the file system and finally by the LBA table. RocksDB and Ceph are two popular key-value stores that perform this function.
When SSDs came along, programmers started to notice that delays caused by this succession of translations became an appreciable part of storage latencies. The hard drives weren't the issue because their own latency was larger than the latency added by these translation steps. That was no longer the case with SSDs, and the translation delays started to draw some attention.
The idea of a key-value SSD was devised to address this problem. It made no sense to perform all those translations to format the data HDD-style when it's not even going to an HDD. So, the idea of managing an SSD as a key-value storage device gained popularity. The result collapsed the interface between the application and the SSD, as shown in Figure 2.
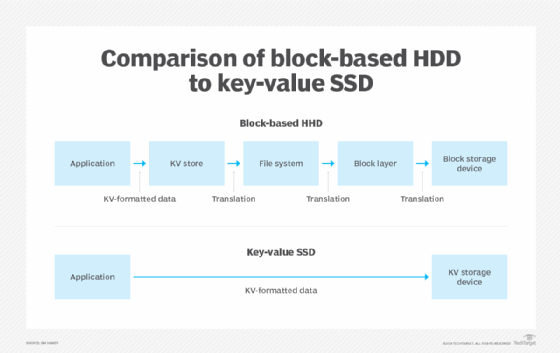
Now that the application's data matches the format the storage device wants to see, data access becomes much faster. But this process has additional benefits.
Away with the block
Key-value storage devices can manage their internal data more efficiently than block devices, and that makes computational storage easier to perform than in block devices.
With block-based storage, a file is mapped to LBAs the host manages. Only the host knows which block belongs to which file.
To visualize this, consider two files: A and B. Each is broken into block-sized pieces -- A0, A1, A2 and so on -- and stored in available blocks in storage. After writes, overwrites and erases, the result might be mapped in an almost random order, like in Figure 3.

If a computational storage device wants to search for a certain pattern within one of these two files, the host must first tell the storage device which blocks to look in. A table of these blocks needs to be transferred from the host to the storage device.
Since key-value storage manages the placement of the value's data internally, it automatically knows where an entire value is. The host doesn't need to take any part in this exercise. If the key-value-based computational storage device wants to search for a pattern within a value, it simply looks within its own internal mapping tables to find where the value is held and searches through that.
There are other uses. For example, if an organization moves, the key-value computational storage device could be commanded to convert all the old headquarters addresses in company documents to the new address. The device could perform significantly more complex operations. Some systems already use this approach to perform video encoding or compression on individual files.
Decreased write amplification
SSDs are made of flash memory, and flash is subject to wear. The more write traffic an SSD receives, the more likely it is to suffer from random bit failures. Flash must also, unfortunately, be erased before it can be overwritten. The minimum erase size is a relatively large flash memory "block," which is different than the LBA block size of a block storage device.
As a result, the internal SSD controller must move valid data around from time to time, and the need increases as the device fills up. In this write amplification, a single write to the SSD may result in multiple internal writes to the flash chips, and that shortens their usable life.
Key-value storage manages large, contiguous areas of flash rather than scattering individual pages across different blocks, as a standard SSD does. When data is erased, it is erased one block at a time, avoiding garbage collection. It reduces the need for data to be moved around within the drive. As a result, there is less write amplification, so there are fewer flash writes. This helps to reduce the amount of wear to the flash chips.
Limitations and standards
Samsung and others have demonstrated the key-value SSD but haven't introduced it as a product yet. When it hits the market, expect the technology to grow in popularity as this new approach gains acceptance.
A number of elements need to fall into place before key-value SSDs can become attractive to the market, however. Most importantly, the optimal performance for a system using these devices can only be attained by reworking parts of the software. In certain cases, this has already been accomplished, but most general-purpose software has not yet been optimized for key-value storage. It may take a few years for this to fall into place.
Another major limitation in a key-value SSD is that data can't be modified in place. When a value is read from the storage device, it must be read as a complete entity, and any modifications must be stored as a complete entity. This enables the key-value storage device to manage where the data is placed.
The fact that the data must be read as a whole also means programs can't reduce I/O accesses by reading only a small part of the entire value. While this is a "cheat" that programmers use to fine-tune performance, it's not a clean practice, so it shouldn't cause much concern.
Since translation delays aren't significant in HDD-based systems, there hasn't been a lot of interest in the development of key-value HDDs. This has influenced the standards process, since the three leading HDD and SSD interface standards are SATA, SAS and NVMe.
SSDs have largely converted to an NVMe I/O protocol, a protocol that was defined with SSDs in mind, and that suits them well. Since SSDs are NVMe and key-value storage is not likely to receive hardware support in HDDs, it only makes sense for NVMe to be the only protocol that supports key-value storage. As a result, the NVMe standard added a Key Value Command Set Specification.
Although the current revision supports key lengths from one to 16 bytes and values of a single byte to tens of megabytes, future revisions could expand the maximum length of either.
The Storage Networking Industry Association has also released a Key Value Storage API Specification to help standardize the communication between applications and key-value SSDs.
Jim Handy is a semiconductor and SSD analyst at Objective Analysis in Los Gatos, Calif.







