Planning NVMe over fabrics? Then get to know all about the Fibre Channel and RDMA fabric options to decide which of the two approaches fits your network best.
When it came time for the NVM Express group to extend nonvolatile memory express over a network, it wisely decided not to choose an emerging transport, such as Intel's Omni-Path, or, even worse, follow the Fibre Channel path and invent a whole new network. Instead, it made NVMe over fabrics modular. That enabled vendors to write the driver to make the NVMe-oF framework run over whatever transport they wanted it to run on and to push their products through the standards process.
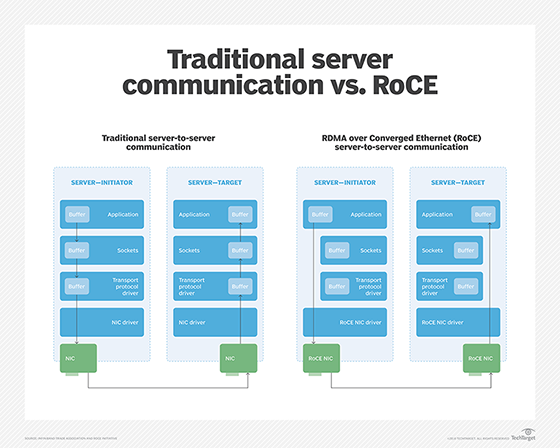
The NVMe-oF 1.0 specification included support for two types of transports: Fibre Channel (FC) and remote direct memory access (RDMA). Both can transfer data from host to array and vice versa without copying the data between memory buffers and I/O cards multiple times as standard TCP/IP stacks do. This zero-copy process -- or mostly zero-copy for FC -- should reduce the CPU load and latency of data transfers. That means any NVMe fabric you choose should speed up your storage performance.
Let's take a look at the NVMe fabric options to consider. InfiniBand, RDMA over Converged Ethernet, RoCE v2 (routable RoCE) and Internet Wide Area RDMA Protocol (iWARP) all fall under the RDMA umbrella.
NVMe over FC
To deliver the consistent low latency NVMe-oF users expect across a network fabric, that fabric must have efficient congestion management mechanisms. NVMe over FC takes advantage of FC's well-established credit buffer congestion control system. Because data isn't transmitted until the sender has received a buffer allocation from the receiver, FC provides reliable, lossless transport. FC host bus adapters (HBAs) have always offloaded the FC Protocol (FCP) to minimize latency and host CPU utilization.
If your storage team can't use Ethernet because the network team would have to be allowed to manage the Ethernet switches, then stick with FC with NVMe.
The entire FC industry is behind NVMe over FC, simplifying the fabric part of things. Any 16 Gbps or 32 Gbps FC HBA or switch will support NVME over FC, while continuing to provide traditional SCSI over FCP services.
If you're happy with your FC infrastructure, NVMe over FC should work well for you. In other words, if your storage team can't use Ethernet because the network team would have to be allowed to manage the Ethernet switches, then stick with FC for your NVMe fabric option.
The RDMA brigade
Network interface cards that connect computers to networks enable direct memory access to save data directly into host memory without copying it into and out of a buffer on the NIC. RDMA extends that capability to read and write memory locations in a remote system. That capability gives you NVMe fabric options other than FC.
How traditional server-to-server communication (left) compares with RoCE server-to-server communication (right).
InfiniBand
RDMA first emerged in the high-performance computing world running across the InfiniBand networks that form the backbone of tightly coupled compute clusters. InfiniBand provides RDMA verbs, such as Write Remote natively, and uses an FC-like buffer credit system to ensure predictable latencies with moderate congestion.
Despite its high bandwidth and low latency, InfiniBand never made it far beyond high-performance computing. The only use case where it gained any traction was as a dedicated back-end network in scale-out storage systems, such as Dell EMC's XtremIO and Isilon.
NVMe over RDMA over Ethernet
Ethernet inventor Bob Metcalfe once famously said, "I don't know what the network of the future will look like, but I'm sure they'll call it Ethernet." Sure enough, over time, Ethernet has taken over more and more storage systems. As Ethernet performance increased, the thought of RDMA over Ethernet started to take hold, even in the high-performance computing world where InfiniBand has been king.
To support RDMA over Ethernet, a new class of NICs has emerged. These RDMA-enabled NICs, called RNICs, accept the RDMA verbs, transmit the data across the network encapsulated in an RDMA-over-Ethernet protocol, and read or write the data to and from memory on the remote system. Like FC HBAs, they offload the RDMA protocol handling.
The problem is, as is often the case, that we have not one but two standard protocols for RDMA over Ethernet. We have RoCE (pronounced Rocky, like the flying squirrel) and iWARP.
While storage over RDMA is appealing for low-latency applications, previous attempts, such as iSER (iSCSI Extensions for RDMA), haven't delivered enough performance to make the necessary network adjustments worthwhile.
RoCE
The original RoCE specification from the InfiniBand Trade Association essentially placed InfiniBand-like RDMA verb traffic directly on Ethernet. The Converged Ethernet in RoCE is a network running data center bridging (DCB), a set of congestion control features that were first designed to make Ethernet lossless. That was done to enable FC over Ethernet.
There's disagreement over just how special Ethernet with DCB is. Every data center Ethernet switch that's 10 Gbps or faster -- any Ethernet switch you'd use for NVMe over RoCE -- supports DCB. So, the Converged Ethernet part of RoCE is easy to get, but it's a bit of work to configure.
The newer RoCE v2 encapsulates the RDMA data in User Datagram Protocol packets, which means that RoCE v2 traffic can be routed just like iWARP traffic. RoCE v2 doesn't even require a lossless network.
Mellanox leads the RoCE movement. Other companies also sell RNICs. Broadcom (both the former Emulex converged network adapters and Broadcom's NIC and LAN-on-motherboard products) and Cavium (recently acquired by Marvell Technology) with its FastLinQ (QLogic) cards support RoCE. There's also a Soft-RoCE driver available for Linux. Attala Systems, which makes NVMe-oF chips, has demonstrated total latency of about 100 microseconds with Mellanox's RNIC and 125 microseconds running Soft-ROCE when accessing NVMe SSDs managed by Attala's field-programmable gate array.
While NVMe over RoCE v2 doesn't require DCB, it still does in the public perception. We expect RoCE to be the NVMe fabric of choice in the highest-performance rack-scale environments.
iWARP
IWARP accepts RDMA verbs and transmits them across the Ethernet encapsulated in TCP packets. While TCP provides the reliable transport, iWARP is almost exclusively implemented in RNICs.
Because iWARP uses TCP for congestion control and reliable transport, iWARP can run across any arbitrary IP transport, including routed networks. That makes it better suited to data center-scale implementations than RoCE, which requires network support.
Microsoft, Intel and RNIC vendor Chelsio Communications lead the iWARP camp. Intel only includes iWARP support in the X722 LAN-on-motherboard component of the Intel C620 series chipsets (Purley). This leaves iWARP users with Marvell's FastLinQ NICs, which uniquely support both RoCE and iWARP, and Chelsio for RNICs.
NVMe over TCP
The latest alternative for an NVMe fabric is the good old TCP. TCP manages congestion and ensures delivery for just about everything we send over Ethernet and everything we send to the internet. NVMe over TCP, promoted primarily by Solarflare and Lightbits Labs, is included in the NVMe-oF 1.1 specification that's now out for final voting and expected to pass by the end of 2018.
Because it runs over standard TCP, NVMe over TCP runs on standard Ethernet gear and doesn't require special RNICs or HBAs. Additional copies of data in typical TCP stacks mean that NVMe over TCP on standard hardware will have higher latency than NVMe over RoCE or iWARP.
Just how much latency TCP will add over an RDMA fabric depends on how you implement NVMe over TCP. Array vendor Pavilion Data has customers running NVMe over RoCE and NVMe over TCP on the same array. They report 100 microsecond latency for RoCE and 180 microseconds for TCP. Others are claiming 10 microseconds to 20 microseconds of additional latency.
Because TCP uses the system processor to manage the protocol and calculate checksums, running NVMe over TCP should also increase the processor load a bit. Many vendors making NVMe-oF target chips are including TCP. Solarflare is building NVMe TCP offloads into its latest NICs.
Some analysts only think of NVMe as a solution for the applications and users that need maximum performance. They question the value of an NVMe fabric that doesn't provide the lowest latency. I think that's a shortsighted view. NVMe over TCP fills the lower-cost, lower-administrative overhead role that iSCSI has played for the past decade. Because it's fully routable, it also supports large-scale deployments better than RoCE.