How to optimize storage for AI, machine learning and deep learning
AI and deep learning apps use large data sets and fast I/O. But storage can cause performance issues. See what features your AI and deep learning storage systems should have.
The resurrection of AI at the hands of machine learning and deep learning has engendered an explosion of research and product development as businesses discover creative ways to use these new algorithms for process automation and predictive insights. The nature of machine learning and deep learning models, the latter of which often emulate the brain's neural structure and connectivity, requires the acquisition, preparation, movement and processing of massive data sets.
Deep learning models, especially, require large data sets. And storage for AI in general, and deep learning in particular, presents unique challenges. A short digression into the nature of machine learning and deep learning software will reveal why storage systems are so crucial for these algorithms to deliver timely, accurate results.
Why storage for AI and deep learning is important
Many researchers have shown that the accuracy of deep learning models improves with larger data sets. The improvement is so significant that researchers often use sophisticated data augmentation techniques to synthetically generate extra data for model training.
For example, this data set from ImageNet used to benchmark various deep learning image classification algorithms contains more than 14 million images with a million annotations. While the ResNet-50 model often used to benchmark image classification hardware is just over 100 MB in size. The models, which ideally are held in memory, must be continually fed with data and that often results in the storage system becoming the bottleneck to overall performance.
Deep learning storage system design must provide balanced performance across a variety of data types and deep learning models.
Regardless of the model and application, deep learning consists of two steps: model training and data inference. Training is where the model parameters are calculated and optimized based on repetitive, often recursive calculations using a training data set. Inference is where the trained model is used on new, incoming data to make classifications and predictions.
Each step can stress the systems that provide storage for AI and deep learning in different ways. With training, the stress results from both the large data sets and fast I/O to the compute complex -- which is often a distributed cluster -- required for acceptable performance. With inference, the stress comes from the real-time nature of data that must be handled with minimal latency.
Storage performance requirements for deep learning
The nature of Deep learning algorithms means they use an enormous amount of matrix math, making them well suited to execution on GPUs initially designed to make thousands of simultaneous floating point calculations on pixel data. Unlike computer graphics, neural networks and other deep learning models don't require high-precision floating point results and are commonly accelerated further by a new generation of AI-optimized GPUs and CPUs that support low-precision 8- and 16-bit matrix calculations, an optimization that can turn storage systems into even bigger performance bottlenecks.
The diversity of deep learning models and data sources, along with the distributed computing designs commonly used for deep learning servers, means systems designed to provide storage for AI must address the following factors:
A wide variety of data formats, including binary large object (BLOB) data, images, video, audio, text and structured data, which have different formats and I/O characteristics.
Scale-out system architecture in which workloads are distributed across many systems, usually four to 16, for training and potentially hundreds or thousands for inference.
Bandwidth and throughput that can rapidly deliver massive quantities of data to compute hardware.
IOPS that can sustain high throughput regardless of the data characteristics; that is, for both many small transactions and fewer large transfers.
Latency to deliver data with minimal lag since, as with virtual memory paging, the performance of training algorithms can significantly degrade when GPUs are kept waiting for new data.
Deep learning storage system design must provide balanced performance across a variety of data types and deep learning models. According to an Nvidia engineer, it's essential to verify storage system performance under a variety of load conditions. He writes,
"The complexity of the workloads plus the volume of data required to feed deep-learning training creates a challenging performance environment. … Given the complexity of these environments, collecting baseline performance data before rolling into production, verifying that the core system -- hardware components and operating system -- can deliver expected performance under synthetic loads, is essential."
Core features of deep learning storage systems
The performance factors described above have pushed vendors of storage systems for AI to adopt five core features, including:
A parallelized, scale-out system design that can be incrementally expanded and where I/O performance scales with capacity. A hallmark of such designs is a distributed storage architecture or file system that decouples logical elements, such as objects and files, from the physical device or devices holding them.
A programmable, software-defined control plane that's key to delivering a scale-out design and enables automation of most management tasks.
Enterprise-grade reliability, durability, redundancy and storage services.
For deep learning training systems, a closely-coupled compute-storage system architecture with a non-blocking networking design to connect servers and storage and a minimum link speed of 10 Gb to 25 Gb Ethernet or EDR (25 Gbps) InfiniBand.
SSD devices, increasingly using faster NVMe devices that deliver higher throughput and IOPS than SATA.
DAS systems typically use NVMe-over-PCIe devices.
NAS designs typically use 10 Gb Ethernet or faster, with NVMe over fabric, InfiniBand or switched PCIe fabric.
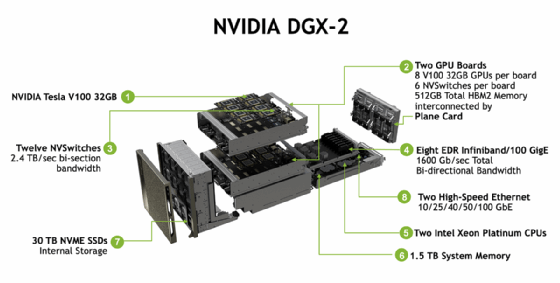
Nvidia's DGX-2 system is an example of a high-performance system architecture for deep learning.
Tailored storage products
AI is a hot technology right now, and vendors have been quickly addressing the market with a mix of new and updated products to address the needs of AI workloads. Given the market dynamism, we won't attempt to provide a comprehensive directory of products optimized or targeted at storage for AI, but the following are some examples:
Dell EMC Ready Solutions for AI with rack-scale bundles, packaging servers, storage, edge switch and a management node. The storage uses Isilon H600 or F800 all-flash scale-out NAS with 40 GbE network links.
DDN A3I uses AI200 or AI400 NVMe all-flash arrays (AFAs) with as much as 360 TB capacity and 750K and 1.5M IOPS respectively and four or eight 100 GbE or EDR InfiniBand interfaces, or the DDN AI7990 hybrid storage appliance with 5.4 petabytes (PB) capacity, 750K IOPS and four 100 GbE or EDR InfiniBand interfaces. DDN also bundles the products with Nvidia DGX-1 GPU-accelerated servers and Hewlett Packard Enterprise Apollo 6500 accelerated servers.
IBM Elastic Storage Server AFA has a variety of SSD-based configurations delivering usable capacity up to 1.1 PB. IBM also has a reference system architecture that combines the Elastic Storage Server with Power Systems servers and the PowerAI Enterprise software stack.
NetApp OnTap AI reference architecture combines Nvidia DGX-1 servers with NetApp AFA A800 systems and two Cisco Nexus 3K 100 GbE switches. The A800 can deliver 1M IOPS with sub-half-millisecond latency, and its scale-out design provides more than 11M IOPS in a 24-node cluster.
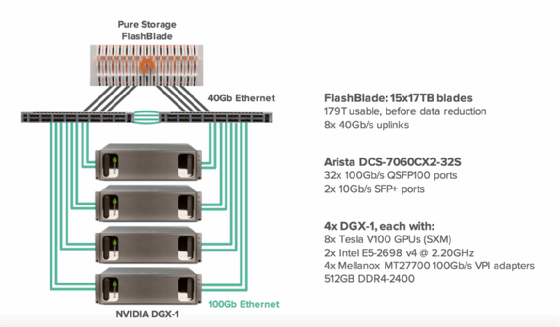
Pure Storage AIRI is another DGX-1 integrated system that uses Pure's FlashBlade AFA system supporting both file and object storage. Reference systems are available with Arista, Cisco or Mellanox switches. For example, an Arista design uses 15 17 TB FlashBlades with eight 40 GbE links to an Arista 32 port 100 GbE switch.
Pure Storage's AIRI system architecture
Deep learning inference systems are less demanding on the storage subsystem and are usually accommodated by using local SSDs in an x86 server. Although inference platforms are generally conventional 1U and 2U server designs with local SSD or NVMe slots, they increasingly include compute accelerators like the Nvidia T4 GPU or an FPGA that can compile some deep learning operations into hardware.