
Photobank kiev - Fotolia
Advantages of object storage and how it differs from alternatives
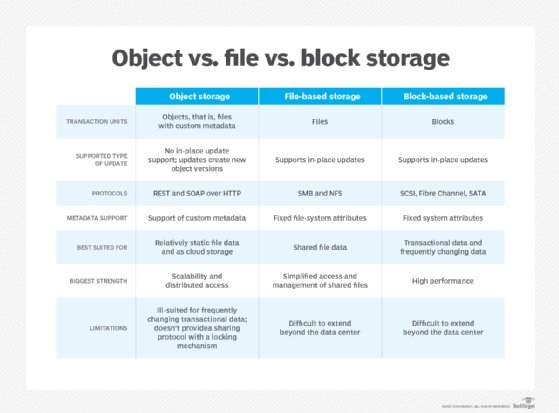
File and block storage might provide better performance, but granular metadata and near-infinite scalability make object storage equally beneficial.
The use cases for file and block storage are well-defined and have been around for decades. Object storage presents a third data storage option. Common questions surrounding object storage may include, "What's different about an object store? When should I use it? What use cases warrant it? How should I go about phasing it into my specific IT infrastructure?" Although a lot has been written about this topic, these questions continue to surface. So what are the advantages of object storage?
Object storage manipulates data in the form of discrete units, or objects. These objects are kept in one repository, not nested as files inside different folders or separate blocks of data to be reassembled. By adding metadata to all of the files, object storage eliminates the hierarchical structure of a file system and gives each file a unique identifier, making it relatively simple to locate within large volumes of data.
Revisiting file and block storage can help define object storage. Comparing the three systems can also help IT shops that might be on the fence and unable to choose which one is right for their data center. While it has benefits, the advantages of object storage may not outweigh those of the alternatives. But first, it's important to understand the intricacies of object storage.
Object storage characteristics
An object is defined as data (typically a file) along with all its metadata, all bundled up. This object is given an ID that is typically calculated from the content of that object (both file and metadata) itself. An object is always retrieved by an application by presenting the object ID to object storage. An object is not limited to any type or amount of metadata. If you choose to, you can assign metadata such as the type of application the object is associated with; the importance of an application; the level of data protection you want to assign to an object; if you want this object replicated to another site or sites; when to move this object to a different tier of storage or to a different geography; and when to delete this object.
This type of metadata goes way beyond the access control lists used in file systems, and is one of the biggest advantages of object storage. The ability to allow users flexibility to define metadata as they wish is unique to object storage. You can start to see how this opens up vast opportunities for analytics that one could never dream of performing before. Given the nature of objects, as described above, performance is not necessarily a hallmark of object storage. But if you want a simple way to manage storage and a service that spans geographies and provides rich (and user-definable) metadata, object storage is the way to go.

Because a lot of development of object storage concepts happened inside Web 2.0 companies trying to build infinitely large storage infrastructures at the lowest cost, most object storage is based on clusters of commodity servers with internal direct-attached storage. There are indeed exceptions to this, most notably DataDirect Networks, and you can certainly use expensive RAID arrays to build an object store, but the rule of thumb is to use commodity hardware. Scaling becomes a simple matter of adding additional nodes. Data protection is generally accomplished by replicating objects to one or more nodes in the cluster, but there are certainly exceptions to this (e.g., Cleversafe and EMC Atmos both use erasure coding to protect data).
Object vs. file
Like file storage, object storage is for unstructured data while block storage is typically used for structured data, such as information inside databases. But while file and object storage both handle the same type of data, they organize and access it differently.
A file storage system is a hierarchical way of organizing files so that an individual file can be located by describing the path to that file. We know that certain attributes -- information that might describe a file and its contents, such as its owner, who can access the file, and its size -- are conveniently stored as metadata in a file system. We also know that network-attached storage (NAS) is the best way to share files securely among users on a network. It works great locally on a LAN but not so well if the users are across a WAN. And managing a single (or a small number) of NAS boxes is trivial, but managing hundreds of them is a nightmare.
The file system is responsible for the placement of data on the NAS box, as well as implementing file sharing by locking and unlocking files as needed. And lastly, file systems work well with hundreds of thousands, and perhaps millions, of files but are not designed to handle billions of files. These limitations were not well understood because many IT shops had not tested those high levels -- until recently. In a nutshell, file storage is great for sharing files locally and if the number of files and the associated metadata are limited. But under the right circumstances, NAS delivers excellent performance for sharing files.
Object storage is that it does not face these same limitations when working with unstructured data. Unlike files and file systems, objects are stored in a flat structure. You have a pool of objects, and you simply ask for a given object by presenting its object ID. Objects may be local or geographically dispersed, but because they are in a flat address space, they are retrieved exactly the same way.
Object vs. block
In block storage, a block is a chunk of data, and the chunks can be combined to create a file. A block has an address, and the application retrieves a block by making a SCSI call to that address. It is a very microscopic way of controlling storage. Unlike in the case of NAS, the application decides where to place the data and how to organize the storage. How the blocks are combined or accessed is left up to the application.
There is no storage-side metadata associated with the block, except for the address, and even that, arguably, is not metadata about the block. In other words, the block is simply a chunk of data that has no description, no association and no owner. It only takes on meaning when the application controlling it combines it with other blocks.
However, under the right circumstances, granting this level of granular control to the application allows it to extract the best performance from a given storage array. This is the reason why block storage has been king of the hill for performance-centric applications, mostly transactional and database-oriented. Adding distance between the application and storage kills this performance advantage due to latency, so most block storage is used locally instead. In a nutshell, key phrases associated with block storage are granularity, great performance, little or no metadata, and local use.
Block storage, as well as file and object storage, is supported by most software-defined storage architectures, though some products may favor individual interfaces.
When comparing object, file and block storage, there are a number of ways to look at it. One of the key advantages of object storage over the other two is its interface. Unlike a file or block, you can access an object using an HTTP-based REST application programming interface. These are simple calls such as Get, Put, Delete and a few others. Their simplicity is an advantage, but they do require changes to the application that were probably written to use SCSI, CIFS or NFS calls. Therein lies the problem. There are ways around this, but the cleanest approach is to change the application code to make direct REST-based calls. So, in a nutshell, an object store is easy to manage, can scale almost infinitely, transcend geographic boundaries in a single namespace and can carry a ton of metadata, but it is generally lower-performance and may require changes to the application code.







