
luchschen_shutter - Fotolia
Flash storage caching boosts application performance, requires balance
Chris Evans discusses the benefits to caching flash storage, the trade-offs involved and flash cache models, as well as a handy cheat sheet.

In a perfect world, we would have the luxury of placing all of our data on the fastest media available. Unfortunately for us, the world of IT isn't perfect.
For practical purposes, we have to match storage to the requirements of applications, for example. Achieving this can be a problem when data profiles change rapidly (i.e., active data changes constantly) because moving data in a tiering model is always a reactive process. Furthermore, as IT becomes more cloud-focused, data and applications may no longer be in the same location, so we also require products that can reference data across distance while maintaining consistency and integrity.
One answer to these I/O performance problems is to implement storage caching. Different from tiering, storage caching maintains a copy of data in a layer of high-performance media while the primary version of that data is kept on the stored copy of the data, usually cheaper disk or flash.
Caching benefits
The advantage of working with copies rather than actual data is that the contents of the cache can rapidly change to match the active workload. Inactive data in the cache, meanwhile, can simply be invalidated and doesn't have to be moved out when the cache becomes full.
Caching also allows for the cost-effective use of multiple media types, as only a small percentage of data is typically active at any one time (perhaps 10% to 20% in most applications). With a relatively small amount of cache, organizations can accelerate a majority of I/O requests to deliver significantly improved application performance at a much lower cost than placing all data on fast media.
Caching trade-offs
For local deployments, storage caching is a trade-off between improving overall I/O performance and the cost of placing data on expensive media. With efficient caching algorithms, a high percentage of I/O (hopefully 90% to 95% or more) will be served to and from cache. Inevitably, some data won't be in cache when required, which means reverting to the primary storage to retrieve that data, resulting in a poor I/O response. In situations where this is likely to be a problem, such as with financial trading systems or online gambling, placing primary data on a faster tier of storage is preferable.
In cloud environments, meanwhile, enterprises can use physical and virtual appliances to cache data locally or within the cloud. This delivers better performance than accessing data directly, as retrieving data over the public internet or even a dedicated network will have much higher latency than a local data center. One drawback to caching data in and out of the public cloud, however, is the issue of consistency in ensuring all I/O write activity is committed back to the primary storage.
Caching models
The following are three main methods of implementing storage caching; which one you pick determines how write I/O requests are handled by the cache:
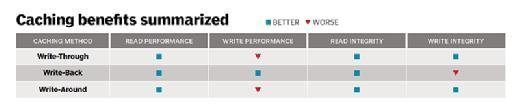
- Write-through. Write requests are written to the cache and to the primary storage before confirmation by the host. The I/O is guaranteed to be on permanent media, but performance is limited by the speed of the primary storage. Because the cache layer doesn't require resiliency (e.g., RAID protection), write-through is cheaper and easier to implement. Read requests are served directly out of the cache if the data is already there, or read from the primary storage and also written to the cache.
- Write-back. This process writes data into the cache and immediately confirms the I/O completion to the host. I/O write performance is good, although the data is more exposed until it is written to the primary storage. Consequently, most implementations of write-back caching protect cache data by mirroring to another host or controller or using battery or UPS backup.
- Write-around. With this model, data is written directly to the primary storage, bypassing the cache, which is then only used for read requests. This type of implementation is used where workload profiles contain large sequential writes that would otherwise pollute the cache with data that is then never subsequently reread (like backup or archive data).
Software implementations of caching typically implement at least one these methods, and can adapt either by detecting workload type or by being configured by volume or LUN.
Caching cheat sheet
Caching methods are based on how write I/O is handled:
- Write-through (writes written to cache and primary storage synchronously).
- Write-back (writes written to cache and primary storage asynchronously).
- Write-around (writes bypass cache and go straight to primary storage).
Caching can be implemented in multiple locations of the I/O stack:
- On an external array (vendor-specific).
- Through an appliance (good for remotely accessed data).
- Hypervisor (accelerating virtual machines [VMs] and benefiting from deduplication).
- Operating system (to extend the basic OS caching features).
- Application (e.g., databases to reduce the read activity of common data).
Where to cache?
Caching is used across the I/O stack in a number of places. You can cache within the application, operating system or hypervisor, as an appliance or within the storage array. The idea with each is to leverage faster media -- dynamic RAM, nonvolatile DRAM (dual inline memory modules) or flash (NAND) -- to improve I/O performance. Examples include:
- External array: Caching within the array has been a feature of external storage systems since EMC introduced the integrated cache disk array under the Symmetrix brand in the early 1990s. The aim of array caching is to reduce the unpredictable I/O performance seen with HDDs, effectively smoothing out I/O and reordering write and read requests to optimize (and effectively minimize) disk head movements. Disk caching, which is -- pretty much -- transparent to the user, is implemented through a mix of DRAM, NVDRAM and flash storage. Array vendors either size cache to the underlying storage, where the cache ratio is fixed, or allow customers to specify cache size as part of the array design or build.
- Appliance-based: Application caching can be achieved through the use of an appliance that extends the visibility of data across the network. These kinds of products are either block- or file-based using typical protocols such as iSCSI, SMB and CIFS, and NFS. Appliances tend to get used where data is accessed over distance, such as across multiple data centers or to and from the public cloud. The caching process can operate in either direction. That is, it can be based on-site -- to provide faster access to cloud resources -- or in the cloud -- to provide faster access to on-premises resources.
- Hypervisor: Hypervisor caching allows flash and DRAM to be used to ameliorate virtual machine performance by placing the most active parts of the VM into faster storage. On VMware's vSphere, this means using flash natively with the "Flash Read Cache" feature, which assigns a certain amount of flash to each VM. There are also third-party tools that will cache both block-based I/O and data stored on NFS data stores within the hypervisor. For Microsoft, Hyper-V caching is implemented directly in the OS or with new features like CSV (Cluster Shared Volumes) Cache, which was introduced in Windows Server 2012. Hypervisor caching can also work well across multiple VMs where data can be deduplicated (like similar virtual desktop infrastructure [VDI] images).
- Operating system: Caching within the OS has been a feature of operating systems from the beginning. The caching process tends to be quite basic and simply done to smooth out I/O response times; though in many cases, caching doesn't consider different I/O profiles. Software vendors have been quick to take this as an opportunity to introduce programs -- many bundled with storage media -- that deliver more efficient caching for Windows and Linux.
- Application caching: Caching is implemented within an application as either part of the database or using bespoke code. Most database platforms implement some kind of caching, including, for example, Oracle SQL Result Cache and Full Database Caching, and MySQL Query Cache.
Vendors caching in
Pretty much all external storage arrays cache I/O in DRAM or NAND flash; although, with all-flash arrays, storage caching may be minimal because overall savings are lower. Below are some specific examples of how vendors implement caching.
Nimble Storage uses NAND flash to cache write I/O based on the assumption that it may be immediately reread. However, NVRAM is used to cache data before committing to disk. Hewlett Packard Enterprise 3PAR uses flash as an extension of DRAM for a secondary layer with less frequently accessed data. This feature, called Adaptive Flash Cache, enables flash to extend the capabilities of array caching without the expense of deploying extra DRAM.
Avere Systems has an appliance-based caching product that extends NAS storage to geographically dispersed data centers or the public cloud. In the public cloud space, this is implemented as a virtual appliance rather than physical hardware. There are also cloud caching products from Microsoft (StorSimple) that cache data written and read from Azure, and Panzura Global File System appliances used to locally cache file data stored in either a public or private cloud.
Within the hypervisor, vendors provide I/O acceleration for both NAS and block protocols. PernixData, for instance, integrates into the VMware ESXi kernel and allows both DRAM and NAND flash to be used to accelerate VM I/O. Where DRAM is used, write I/Os are replicated between multiple hosts in a cluster to protect against hardware failure. Infinio Accelerator software caches both NAS and block-based I/O for virtual machines. This is achieved through the use of a VM on each VMware vSphere host that uses DRAM within the virtual machine as the cache. SanDisk, for its part, provides caching under the FlashSoft brand. The latest, 4.0, release supports vSphere 6 and Microsoft Hyper-V (and Server), while older versions support Linux and vSphere ESXi 5.x.
At the OS layer, there are a number of software products for accelerating performance. Enmotus offers a range of products for improving traditional disk-based performance using flash for either workstations or servers, for example, while Intel's Cache Acceleration Software works in conjunction with its range of SSD products. The software supports Windows and Linux and can be run as a VM under all common hypervisors. Additional OS-based caching products include ION Accelerator (SanDisk), AutoCache (Samsung) and XtremCache (EMC).
Lastly, Atlantis Computing has two caching products, one targeted at VDI (ILIO) and the other for virtual server environments (USX). ILIO supports both persistent and nonpersistent desktops using DRAM with a high level of deduplication to deliver much more effective VDI total cost of ownership than using external flash-based storage.
Caching out
Caching can improve application performance in many places. Deciding where to cache requires balancing cost savings (license avoidance, hardware cost avoidance) with practicality of implementation, however. And while highly virtualized environments usually benefit from caching in the hypervisor, some tactical implementations -- such as caching directly within a VM or assigning SSD to a database -- may also prove useful.
About the author:
Chris Evans is an independent consultant with Langton Blue.






