Big data storage architecture: Categories, strengths and use cases
We explore distributed nodes, scale-out NAS, all-SSD arrays and object storage as choices for a storage architecture for big data.

What you will learn: Big data storage architecture is changing to deal with the ever-growing volume of data companies are keeping and analyzing to gain a competitive advantage in the market. Today, organizations are looking for a storage architecture with enough bandwidth to handle large file sizes, that is able to scale up by adding spindles and is easier to scale out to billions of data objects.
Storage architectures for big data can be grouped into four categories: widely distributed nodes, scale-out network-attached storage, all-solid-state drive arrays and object-based storage. Each has its own set of strengths and use cases. And, of course, they're not mutually exclusive, so some organizations may use more than one.
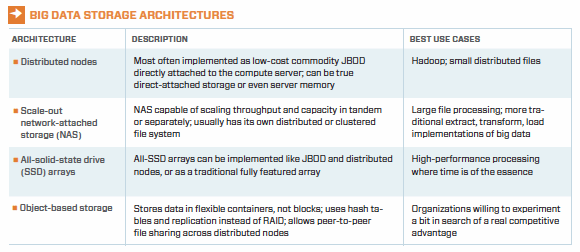
Distributed nodes may be widely distributed geographically. A distributed architecture is commonly associated with grid computing because it can scale in tandem with the compute environment. The obvious application for this is many small files; it is most closely associated with Hadoop, where low-cost commodity hardware is intended and may be the lowest-cost option.
In some cases, organizations will choose to use a server's direct-attached storage and even host memory. While this can certainly have the benefit of easy implementation, this kind of "back to the future" architecture carries all the limitations that discredited it in the first place. Those include a lack of scalability, relatively slow devices (in the case of internal hard disk drives [HDDs]) and difficult management.
Most widely distributed environments will place JBOD-like systems close to the computing environment to match throughput, data location and compute power all in the same place. The architecture is "shared nothing," which means compute nodes don't share the data as they would in a network-attached storage (NAS) configuration. JBOD also doesn't come with data management functionality. Data services can be gained through third-party software if they're necessary.
Scale-out NAS might not fit the Hadoop definition of low-cost commodity hardware, but it certainly has its place in big data analytics. Scale-out NAS systems have the ability to scale throughput and capacity in tandem or independently. Moreover, unlike JBOD, most scale-out NAS comes fully featured, including automated storage tiering. Tiering allows administrators to tune the system for both optimum performance and lowest cost per gigabyte stored.
High-end, scale-out NAS systems can accommodate tens of petabytes of data, sufficient for most commercial applications. They also include their own distributed or clustered file system, which may benefit some analytical applications but limits the ingestion of data to certain formats or requires extract, transformation and load preprocessing. Scale-out NAS can certainly manage millions or billions of small files, but its greatest strength may be for large file processing.
All-solid-state drive (SSD) arrays suffer from the perception that they're very expensive and thus might not seem like a logical alternative for big data. However, as noted earlier, the value of competitive advantage may exceed the cost of infrastructure. Given that big data is a real-time process where I/O is the likely bottleneck, all-SSD arrays may yield information several times faster than more traditional architectures.
For more information on big data environments and big data analytics
Selecting the correct technology to analyze big data
All-SSD arrays aren't monolithic in nature and can be deployed in a JBOD-like manner for Hadoop. (Allow us to be the first to coin the acronym "JBOSSD.") Although SSDs remain relatively expensive compared to HDDs, the cost differential has been narrowing rapidly over the past few years on a per-gigabyte basis; SSD technology has a significant cost advantage on a per-IOPS basis. When hundreds of thousands of IOPS are needed, there may be no substitute for SSDs.
Object-based storage is in its commercial infancy, but it may have significant benefits for big data. It can be deployed on distributed nodes of JBOD hardware, yet maintain data consistency across the distributed network. It also uses replication and distributed hash tables rather than RAID to ensure data recoverability. In addition, it can use BitTorrent, a protocol for peer-to-peer file sharing. Instead of operating at the block level, object storage uses flexibly sized data containers (perhaps perfect for unpredictable data types).
In theory, object storage is highly scalable and well suited to big data, but commercial proof remains scant. Organizations willing to explore for a real competitive edge may be interested in at least prototyping an object storage implementation.
About the author:
Phil Goodwin is a storage consultant and freelance writer.







