4 sources of storage latency and PMem's emerging role
Controllers, the software stack, and external and internal interconnects have an outsized impact on storage latency. Learn about their affects and how PMem is countering latency.
As flash SSDs have become ubiquitous, many IT pros think storage performance issues are a thing of the past. News flash: They're not.
Ever wonder why the total IOPS or throughput of a storage system or software-defined storage (SDS) is nowhere near the sum of the flash SSDs used? Flash SSDs are just one piece of the storage system or SDS performance puzzle. And they're not the biggest piece. There are four other sources of storage latency that can affect storage system performance. They include:
Storage controllers
Storage software stacks
External interconnects
Internal interconnects
In this article, we'll look at the effect each of these areas has on performance. In addition, we'll examine what's next with the emergence of persistent memory, or PMem, and how it will affect sources of storage latency and performance.
What is storage latency?
Storage performance is measured in first byte latency, tail latency, read IOPS, write IOPS, random IOPS (mix of read and write commonly with a 70/30 split), sequential throughput reads and sequential throughput writes.
Storage IOPS is typically measured as 4 KB IOPS, even though many applications are 8 KB, 32 KB and even 64 KB. Storage throughput is rated as megabytes per second or gigabytes per second and, often, calculated by multiplying the IOPS payload by the number of IOPS. IOPS is critical for transactional data that is common in a relational database. Throughput is critical for analytical applications, such as AI; machine learning; deep learning; data warehouses; big data analytics; and high-performance computer applications in laboratories, pharmaceuticals, vaccines and energy.
Storage latency is an important aspect of storage performance. IOPS without latency measurements is meaningless. Latency dictates individual I/O operation responsiveness. Take a storage system or an SDS that produces 250,000 IOPS at 1 millisecond of average latency. That's a somewhat mediocre performance. If the average latency required is closer to 200 microseconds, that storage system may only be able to deliver 50,000 IOPS.
These five technologies -- storage controllers, the storage software stack, and external and internal interconnects, as well as PMem -- are good places to pay attention to when getting rid of sources of storage latency.
The best way to measure storage latency is to start from the moment a request for data is issued to the storage layer and stop when the requested data arrives or there's confirmation the data is stored on the drive. First byte latency is the latency of the first byte of the requested data. The impact of tail latency -- the time it takes for the last byte to arrive -- is more important to messaging applications requiring synchronization, which are common in high-performance compute multipath I/O applications.
A storage system or SDS that fails to account for the synergy of all the aforementioned technologies won't deliver optimized performance. A deeper dive shows why. And because latency has an oversized impact on IOPS and throughput, it's a good place to start. What follows is a look at four sources of latency in modern storage systems.
1. Storage controllers
Latency is another term for delay. It's the amount of time for something to occur. At every point in the path between the application and the storage media, there are many opportunities for latency. They include the application server with its CPU, memory, file system, PCIe controller PCIe bus, network interface card and other components to the target NIC or adapter on the storage system, which has its own set of latency-causing components. Each step adds latency, and keeping that latency down requires optimization at each point in the path.
Storage systems have a purpose-built or a general-purpose server storage controller or controllers. The most common storage systems have two active-active storage controllers. SDS may or may not have dedicated storage controllers. SDS systems are just as likely to be part of a hyper-converged infrastructure (HCI) as they are to have dedicated storage controllers. A storage controller is a server, and it has an enormous effect on latency, reads, writes, IOPS and throughput.
The controller's CPU itself adds storage latency. The amount of latency varies by CPU. There are four primary server CPU types: Intel Xeon, AMD, IBM Power and Arm. Not all CPUs are created equal. Some have more cores than others. IBM Power has more L2, L3 and L4 cache and is RISC-based. Intel Xeon, AMD and Arm are CISC-based. Arm is generally lower powered, but Intel has some lower powered variations. Intel can also uniquely use its 3D XPoint lower latency persistent non-volatile memory in a DIMM slot.
2. The storage software stack
SDS in HCI shares the CPU with the hypervisor, VMs, containers and applications. Therefore, there's less CPU and memory available for the storage stack and read/write I/Os. This leads to some contention and additional latency.
Substantial latency frequently comes from the storage software stack itself. That stack includes most storage services, including load balancing, RAID, erasure coding, error detection and correction, snapshots, clones, replication, mirroring, analytics, predictive insights and reporting. All these services consume CPU and memory resources. When a given CPU-intensive storage service is running in the CPU -- such as a RAID drive rebuild, snapshot or simple erasure coding -- it can add significant CPU read/write latencies. Most storage software stacks weren't written with CPU and memory efficiencies as a focus.
Efficiency was commonly deemed unnecessary as long as Moore's law held. Moore's law stated that a CPU's performance doubled every two years; it had originally been every 18 months. That doubling in performance made software efficiency a waste of time. Not anymore, however. CPUs are no longer hitting that critical Moore's law benchmark. Quantum physics has reared its ugly head, and CPU gains have slowed to a crawl. This, in turn, has forced storage systems and SDS vendors to get more creative architecturally to increase performance.
StorOne is one vendor that focuses on the storage software stack efficiencies. More efficient software frees up CPU cycles for read/write. This is a nontrivial exercise, requiring lots of time and effort.
A few other vendors, like Hitachi Vantara, are using field-programmable gate arrays, and Fungible and Mellanox Technologies are using ASICs designed to offload parts of the storage software stack to free up cycles. Several vendors, including Dell EMC, Hewlett Packard Enterprise, IBM and NetApp, implement scale-out storage architectures that add additional controllers, CPUs, cores and cycles to the system, while also adding rack space, cables and switches, among other things.
Fungible combines offload with scale-out. Whereas, Pavilion Data Systems scales in, adding more controllers and CPUs, internally spreading the software load, connected via high-performance PCIe switching. It's important to note how a storage system is scaled-out. It can mean diminishing marginal returns on each additional controller, limiting the maximum number. How effectively a storage vendor solves the CPU issues goes a long way toward solving storage read/write latencies.
3. External interconnect
The external interconnect is yet another major source of storage latency. Many storage pros focus on network bandwidth rather than latency. It's not that bandwidth isn't important; it is, especially for parallel file system applications. The NICs, adapters, PCIe generation, port bonding and switches all have an impact on bandwidth. NICs, adapters, and switches range from 1 Gbps to 400 Gbps per port. However, PCIe Gen 3 bandwidth tops out at 128 Gbps with 16 lanes, meaning it can't really support 200 to 400 Gbps ports. PCIe Gen 4 has two times the bandwidth of Gen 3, and PCIe Gen 5 has two times the bandwidth of Gen 4.
But storage latency is the more pervasive and generally applicable performance issue. Standard TCP/IP Ethernet used for NFS, SMB and iSCSI has the highest networking latencies. Fibre Channel (FC) has the next highest latency. Remote direct memory access networks -- such as InfiniBand; RDMA over converged Ethernet (RoCE); and NVMe-oF running on InfiniBand, Ethernet, FC and TCP/IP Ethernet -- provide the lowest networking latencies. RDMA radically reduces external latencies between the application servers and the storage system or SDS, bypassing the CPU and going directly to memory. Its latencies are equivalent to those of internal direct-attached storage. The amount of memory in each controller becomes important in minimizing latency and maximizing performance.
Some argue that the external interconnect between applications and SDS is irrelevant when running in HCI, but that would be incorrect. There are multiples nodes in most HCI clusters. The latency between an application in one node and the storage in another is greatly affected by the external interconnect, just like it is for storage systems and standalone SDS.
4. Internal interconnect
The next storage latency source is the internal interconnect. NVMe is the lowest latency, highest performance flash SSD interface today. It also uses a PCIe bus interconnect. Most CPUs have a limited number of PCIe slots. Some of those are required for the external interconnect. Some may be used by GPUs or other for functions. There's a hard limit on the number of NVMe drives that can be connected to a specific storage controller. Increasing that number, requires either more interconnect controllers, a PCIe switch or both.
Most all-flash arrays have been using SAS/SATA flash SSDs. The SAS/SATA controller adds another latency hop in the path. Additionally, SATA drive bandwidth is limited to 6 Gbps, whereas SAS drive bandwidth is limited to 24 Gbps. These interconnects have less bandwidth and significantly more latency.
How persistent memory can optimize storage performance
And then there's the newest non-volatile media called 3D XPoint (Intel brands it as Optane). 3D XPoint is faster with higher write endurance than NAND flash, but it's slower than dynamic RAM (DRAM). It's available as an NVMe drive, called storage class memory (SCM), and as a DIMM, called PMem.
Storage class memory is slower than DRAM but faster than flash.
SCM drives are available from Intel and Micron. PMem is only available from Intel. SCM is approximately three times faster than NVMe NAND flash drives. Unfortunately, the cost justification is the problem; SCM drives cost considerably more than three times on a per gigabyte basis. Even so, Dell EMC, StorOne and Vast Data offer SCM drives as a high-performance tier in their architectures.
PMem is a different story and could be a more immediate way to eliminate sources of storage latency. It connects to the memory bus via a DIMM slot. Capacities are double that of DRAM DIMMs, topping off at 512 GB or, approximately, 3 TB of PMem per server. But every PMem module must be paired with a DRAM module. PMem latency is about 25 times higher than DRAM, but it's more than 80 times lower than NVMe flash.
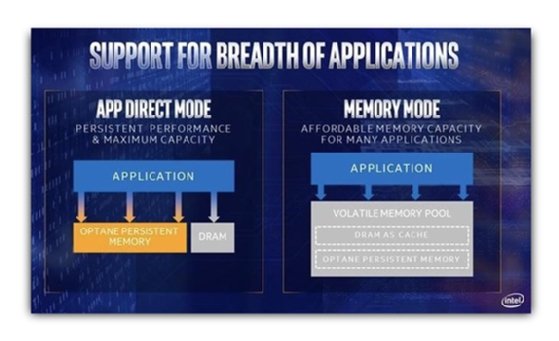
Intel's PMem has two operating modes -- Memory Mode and App Direct Mode. Memory Mode turns PMem into volatile memory because PMem uses DRAM as cache to make it transparent to applications. App Direct Mode has four variations. All of them require application modifications to use PMem as an extremely high-performance storage tier.
Intel Optane persistent memory has two modes: Memory Mode or App Direct Mode.
As of this writing, only Oracle has implemented PMem in its Exadata system's storage. It uses 100 Gbps RoCE to connect the Exadata database servers to the storage servers. The system allows all Exadata database servers access to all PMem in the storage servers. Oracle can provide up to 1.5 TB of PMem per storage server, 27 TB per rack and nearly half a petabyte per system. Expect other storage vendors to implement this approach soon.
In summary, each of these technologies -- storage controllers, the storage software stack, and external and internal interconnects, as well as PMem -- have an outsized impact on the performance of storage systems and SDS in terms of latency, IOPS, throughput and bandwidth. These areas are good places to pay attention to when fine-tuning your enterprise storage and getting rid of sources of storage latency.