storage virtualization
What is storage virtualization?
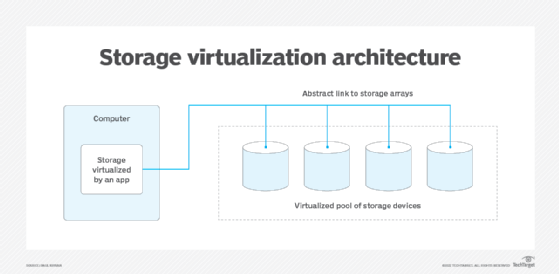
Storage virtualization is the pooling of physical storage from multiple storage devices into what appears to be a single storage device -- or pool of available storage capacity. A central console manages the storage.
The technology relies on software to identify available storage capacity from physical devices and to then aggregate that capacity as a pool of storage that can be used by traditional architecture servers or in a virtual environment by virtual machines (VMs).
The virtual storage software intercepts input/output (I/O) requests from physical or virtual machines and sends those requests to the appropriate physical location of the storage devices that are part of the overall pool of storage in the virtualized environment. To the user, the various storage resources that make up the pool are unseen, so the virtual storage appears like a single physical drive, share or logical unit number (LUN) that can accept standard reads and writes.
A basic form of storage virtualization is represented by a software virtualization layer between the hardware of a storage resource and a host -- a PC, a server or any device accessing the storage -- that makes it possible for operating systems (OSes) and applications to access and use the storage.
Even a redundant array of independent disks, or RAID, array can sometimes be considered a type of storage virtualization. Multiple physical drives in the array are presented to the user as a single storage device that, in the background, stripes and replicates data to multiple disks to improve I/O performance and to protect data in case a single drive fails.
Types of storage virtualization: Block vs. file
There are two basic methods of virtualizing storage: file-based or block-based. File-based storage virtualization is a specific use, applied to network-attached storage (NAS) systems. Using Server Message Block in Windows server environments or Network File System protocols for Linux systems, file-based storage virtualization breaks the dependency in a normal NAS array between the data being accessed and the location of physical memory.
The pooling of NAS resources makes it easier to handle file migrations in the background, which will help improve performance. Typically, NAS systems are not that complex to manage, but storage virtualization greatly simplifies the task of managing multiple NAS devices through a single management console.
Block-based or block access storage -- storage resources typically accessed via a Fibre Channel (FC) or Internet Small Computer System Interface (iSCSI) storage area network (SAN) -- is more frequently virtualized than file-based storage systems. Block-based systems abstract the logical storage, such as a drive partition, from the actual physical memory blocks in a storage device, such as a hard disk drive (HDD) or solid-state memory device. Because it operates in a similar fashion to the native drive software, there's less overhead for read and write processes, so block storage systems will perform better than file-based systems.
The block-based operation enables the virtualization management software to collect the capacity of the available blocks of storage space across all virtualized arrays. It pools them into a shared resource to be assigned to any number of VMs, bare-metal servers or containers. Storage virtualization is particularly beneficial for block storage.
Unlike NAS systems, managing SANs can be a time-consuming process. Consolidating a number of block storage systems under a single management interface that often shields users from the tedious steps of LUN configuration, for example, can be a significant timesaver.
An early version of block-based virtualization was IBM's SAN Volume Controller, now called IBM Spectrum Virtualize. The software runs on an appliance or storage array and creates a single pool of storage by virtualizing LUNs attached to servers connected to storage controllers. Spectrum Virtualize also enables customers to tier block data to public cloud storage.
Another early storage virtualization product was Hitachi Data Systems' TagmaStore Universal Storage Platform, now known as Hitachi Virtual Storage Platform. Hitachi's array-based storage virtualization enables customers to create a single pool of storage across separate arrays, even those from other leading storage vendors.
How storage virtualization works
To provide access to the data stored on the physical storage devices, the virtualization software needs to either create a map using metadata or, in some cases, use an algorithm to dynamically locate the data on the fly. The virtualization software then intercepts read and write requests from applications. Using the map it has created, it can find or save the data to the appropriate physical device. This process is similar to the method used by PC OSes when retrieving or saving application data.
Storage virtualization disguises the actual complexity of a storage system, such as a SAN, which helps a storage administrator perform the tasks of backup, archiving and recovery more easily and in less time.
In-band vs. out-of-band virtualization
There are generally two types of virtualization that can apply to a storage infrastructure:
- In-band virtualization -- also called symmetric virtualization -- handles the data that's being read or saved and the control information, such as I/O instructions and metadata, in the same channel or layer. This setup enables the storage virtualization to provide more advanced operational and management functions such as data caching and replication services.
- Out-of-band virtualization -- or asymmetric virtualization -- splits the data and control paths. Since the virtualization facility only sees the control instructions, advanced storage features are usually unavailable.
Virtualization methods
Storage virtualization today usually refers to capacity that is accumulated from multiple physical devices and then made available to be reallocated in a virtualized environment. Modern IT methodologies, such as hyper-converged infrastructure (HCI) and containerization, take advantage of virtual storage, in addition to virtual compute power and often virtual network capacity.
Although waning as a backup target media, tape storage is still widely used for archiving infrequently accessed data. Archival data tends to be voluminous; tape media can employ storage virtualization to make it easier to manage large data stores. Linear tape file system is a form of tape virtualization that makes a tape look like a typical NAS file storage device and makes it much easier to find and restore data from tape using a file-level directory of the tape's contents.
There are multiple ways storage can be applied to a virtualized environment:
- Host-based storage virtualization is software-based and most often seen in HCI systems and cloud storage. In this type of virtualization, the host, or a hyper-converged system made up of multiple hosts, presents virtual drives of varying capacity to the guest machines, whether they are VMs in an enterprise environment, physical servers or PCs accessing file shares or cloud storage. All of the virtualization and management are done at the host level through software, and the physical storage can be almost any device or array. Some server OSes have virtualization capabilities built in, such as Windows Storage Spaces.
- Array-based storage virtualization most commonly refers to the method in which a storage array acts as the primary storage controller and runs virtualization software, enabling it to pool the storage resources of other arrays and to present different types of physical storage for use as storage tiers. A storage tier may comprise solid-state drives or HDDs on the various virtualized storage arrays; the physical location and specific array is hidden from the servers or users accessing the storage.
- Network-based storage virtualization is the most common form that enterprises use. A network device, such as a smart switch or purpose-built server, connects to all storage devices in an FC or iSCSI SAN and presents the storage in the network as a single, virtual pool.
Benefits and uses of storage virtualization
When first introduced more than two decades ago, storage virtualization tended to be difficult to implement and had limited applicability. Because it was originally host-based, storage virtualization software had to be installed and maintained on all servers needing access to the pooled storage resources. As the technology matured, organizations could implement it in a variety of ways, which made it easier to deploy in a variety of environments. Users could choose the virtualization method that made the most sense for their shops' existing infrastructure.
Further development of virtualization software, along with standards such as the Storage Management Initiative Specification, enabled virtualization products to work with a wider variety of storage systems, making it a more attractive option for enterprises struggling with spiraling storage capacities.
Some of the benefits and uses of storage virtualization are the following:
- Easier management. A single management console to monitor and maintain multiple virtualized storage arrays cuts down on the time and effort necessary to manage the physical systems. This is particularly beneficial when storage systems from multiple vendors are in the virtualization pool.
- Better storage utilization. Pooling storage capacity across multiple systems makes it easier to allocate so the capacity is more efficiently allocated and used. With unconnected, disparate systems, it's likely some systems will end up operating at or near capacity, while others are barely used.
- Extended life of older storage systems. Virtualization offers a great way to extend the usefulness of older storage gear by including them in the pool as a tier to handle archival or less critical data.
- Universal advanced features. Enterprises can implement some more advanced storage features like tiering, caching and replication at the virtualization level. This helps standardize these practices across all member systems and can deliver these advanced functions to systems that may lack them.
Editor's note: This article was revised in 2023 by TechTarget editors to improve the reader experience.







