redundant
What is data redundancy?
Data redundancy refers to the practice of keeping data in two or more places within a database or data storage system. Data redundancy ensures an organization can provide continued operations or services in the event something happens to its data -- for example, in the case of data corruption or data loss. The concept applies to areas such as databases, computer memory and file storage systems.
Data redundancy can occur within an organization intentionally or accidentally. If done intentionally, the same data is kept in different locations with the organization making a conscious effort to protect it and ensure its consistency. This data is often used for backups or disaster recovery.
If carried out by accident, duplicate data may cause data inconsistencies. Even though data redundancy can help minimize the chance of data loss, redundancy issues can affect larger data sets. For example, data that is stored in several places takes up valuable storage space and makes it difficult for the organization to identify which data they should access or update.
The word redundant can also be used as an independent technical term to refer to the following:
- Computer or network system components that are installed to back up primary resources in case they fail.
- Redundant information that is unneeded or duplicated.
- Redundant bits or extra binary digits that are generated and moved with a data transfer to ensure that no bits were lost during the data transfer.
- Redundant data that protects a storage array against data loss in the event of a hard disk failure.
How does data redundancy work?
Data needs to be stored in two or more places for it to be considered redundant. If the primary data becomes corrupted, or if the hard drive the data is on fails, then the extra set of data provides a fail-safe the organization can shift to.
The redundant data can be either a whole copy of the original data or select pieces of data. Keeping select pieces of data enables an organization to reconstruct lost or damaged data. Hard drives with copies of data are stored in an array, so if something happens to the original data, the array can kick in with little to no downtime. In addition, redundancy measures can be accomplished through backups or RAID systems.
Benefits and drawbacks of data redundancy
Data redundancy has benefits or risks depending on the implementation. Potential benefits include the following:
- Helps protect data. When data cannot be accessed, redundant data can help replace or rebuild missing data.
- Data accuracy. Hosting multiple locations for the same data means that a data management system can evaluate any differences, meaning data is assured to be accurate.
- Access speed. Some locations for data may be easier to access than others for an organization that spans different physical areas. A person within an organization may access data from redundant sources to have faster access to the same data.
However, some possible downsides include the following:
- Increase in database sizes. More storage space is needed for a redundant copy of a large amount of data. A larger database may also cause longer load times or create confusion if employees do not know where certain data is stored.
- Cost. More need for storage also means an increased cost in addition to any extra overhead or resources needed to maintain and update redundant data.
- Data discrepancies. Storing data in multiple locations can cause discrepancies such as missing records or incorrect values if the data is not continually updated.
- Corruption. Storing multiple copies of the same data increases the chance of data corruption. Damaged data could result from errors in writing, reading, storage or processing of data.
Redundancy in storage
When it comes to usage of storage, redundancy can be a safeguard or take the form of unwanted overhead. Data volumes will often contain redundant storage blocks. A deduplication process may remove these redundant blocks to reduce storage consumption within the volume or to minimize the volume of data that must be backed up.
Many organizations intentionally create redundant copies of data to minimize the chance of data loss. This redundancy may exist as mirrored virtual machines (VMs), storage volumes or as an offsite, synchronized data copy.
Data redundancy vs. backup
Data redundancy and backups are both intended to prevent data loss, but the two technologies are slightly different. Data redundancy often takes the form of a synchronized copy of the organization's data. For example, an organization might create a redundant VM or storage volume.
Data redundancy can help to prevent service outages. For example, if a VM were to fail, a replica VM could quickly be brought online to minimize the service disruption.
Backups, on the other hand, are copies of data and other resources. Backups are specifically for creating copies of data in case an organization experiences an incident where data loss occurs, such as to buggy software, data corruption, hardware failure, malicious hacking, user error or other unforeseen events. Where redundancy is about making sure a business is able to provide continuity in services, backups are more about bringing a system back to a previous state.
But there is an overlap between redundancy and backups. Backups and some data redundancy products offer point-in-time recovery capabilities, but redundancy products generally have fewer recovery point options. Backups are also a good choice for granular recovery, which enables an organization to use a single backup operation to recover both files and images. In contrast, redundant systems are better suited to situations in which the organization needs to keep critical systems online and cannot tolerate a long recovery period.
Redundancy in RAID
RAID is one of the most common forms of data redundancy. RAID arrays are designed to provide better performance and reliability than what is possible using a single disk.
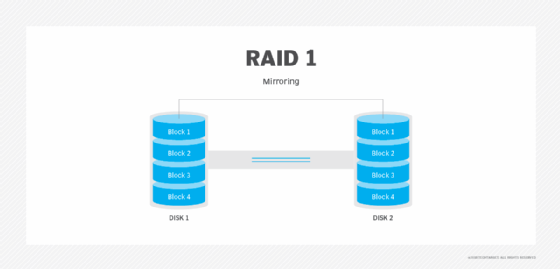
RAID refers to several different storage architectures, which are known as RAID levels. Not all RAID levels provide data redundancy, but most do. RAID 1, for instance, mirrors disks so an exact copy of the disk can be used if the primary copy fails.
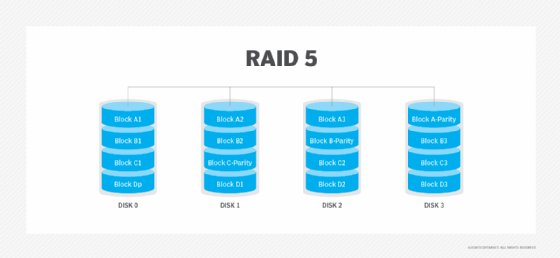
RAID 5 provides redundancy through the use of parity. Data is striped across all the disks in the array in a way that spans less data across multiple disks. Each disk also contains parity information that can keep the array working in the event of a disk failure. When a failed disk is replaced, the parity information is used to reconstruct the contents of the failed disk onto the new disk.
There are many other RAID levels that protect data through redundancy. Parity and mirroring are two of the most common examples.
Data redundancy alternatives
If an organization does not want to rely solely on data redundancy, there are other alternatives to data protection or recovery. For example, there are backups, continuous data protection (CDP), snapshots and image-based backups.
- Backups bring a system back to a previous state. The goal is to ensure rapid and reliable data retrieval, if needed.
- CDP protects data on a nearly continuous basis. CDP products work by initially replicating data to a disk-based backup on a block-by-block basis. Software then monitors data for changes to the stored blocks or the creation of new blocks. When a block is created or modified, it is backed up. An index tracks versioning information and data deduplication ensures only unique blocks are stored on the backup media.
- Snapshots never create a copy of data. Instead, they create a partial image of a VM, file or application at a point in time. Snapshots enable an organization to roll data back to an earlier point in time if something goes wrong.
- Image-based backups are similar to snapshots but capture an image of a VM as a whole. If a recovery operation is required, then a copy of the VM is usually mounted in a sandbox environment so the data can be extracted.
Learn which seven additional factors to consider in network redundancy design, including network protocols, processors and WANs.






