race condition
What is a race condition?
A race condition is an undesirable situation that occurs when a device or system attempts to perform two or more operations at the same time, but because of the nature of the device or system, the operations must be done in the proper sequence to be done correctly.
Race conditions are most commonly associated with computer science and programming. They occur when two computer program processes, or threads, attempt to access the same resource at the same time and cause problems in the system.
Race conditions are considered a common issue for multithreaded applications.
What are examples of race conditions?
A simple example of a race condition is a light switch. In some homes, there are multiple light switches connected to a common ceiling light. When these types of circuits are used, the switch position becomes irrelevant. If the light is on, moving either switch from its current position turns the light off. Similarly, if the light is off, then moving either switch from its current position turns the light on.
With that in mind, imagine what might happen if two people tried to turn on the light using two different switches at the same time. One instruction might cancel the other or the two actions might trip the circuit breaker.
In computer memory or storage, a race condition may occur if commands to read and write a large amount of data are received at almost the same instant, and the machine attempts to overwrite some or all of the old data while that old data is still being read. The result may be one or more of the following:
- the computer crashes or identifies an illegal operation of the program
- errors reading the old data
- errors writing the new data
A race condition can also occur if instructions are processed in the incorrect order.
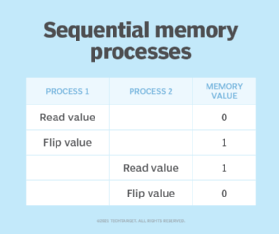
Suppose two processes need to perform a bit flip at a specific memory location. Under normal circumstances the operation should work as shown in Figure 1.
If a race condition occurred causing these two processes to overlap, the sequence of operations could potentially look more like what's shown in Figure 2.

Race conditions occasionally occur in logic gates when inputs come into conflict. Because the gate output state takes a finite, nonzero amount of time to react to any change in input states, sensitive circuits or devices following the gate may be fooled by the state of the output and not operate properly.
What are the types of race conditions?
There are a few types of race conditions. Two categories that define the impact of the race condition on a system are referred to as critical and noncritical:
- A critical race condition will cause the end state of the device, system or program to change. For example, if flipping two light switches connected to a common light at the same time blows the circuit, it is considered a critical race condition. In software, a critical race condition is when a situation results in a bug with unpredictable or undefined behavior.
- A noncritical race condition does not directly affect the end state of the system, device or program. In the light example, if the light is off and flipping both switches simultaneously turns the light on and has the same effect as flipping one switch, then it is a noncritical race condition. In software, a noncritical race condition does not result in a bug.
Critical and noncritical race conditions aren't limited to electronics or programming. They can occur in many types of systems where race conditions happen.
In programming, two main types of race conditions occur in a critical section of code, which is a section of code executed by multiple threads. When multiple threads try to read a variable and then each acts on it, one of the following situations can occur:
- Read-modify-write. This kind of race condition happens when two processes read a value in a program and write back a new value. It often causes a software bug. Like the example above, the expectation is that the two processes will happen sequentially -- the first process produces its value and then the second process reads that value and returns a different one.
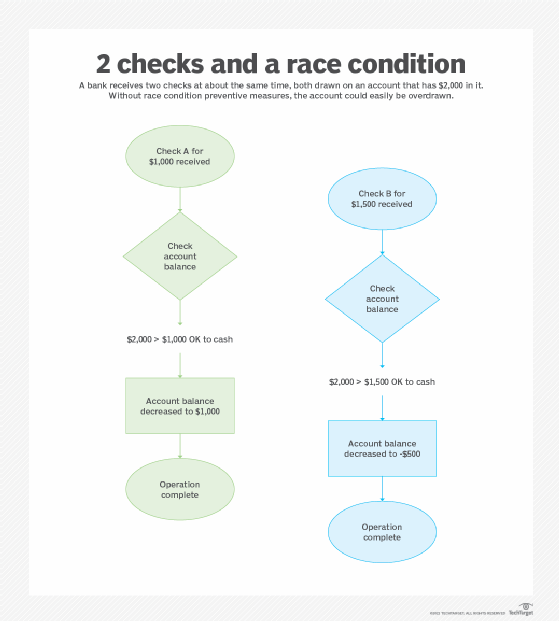
For example, if checks against a checking account are processed sequentially, the system will make sure there are enough funds in the account to process check A first and then look again to see if there are enough funds to process check B after processing check A. However, if the two checks are processed at the same time, the system may read the same account balance value for both processes and give an incorrect account balance value, causing the account to be overdrawn.
- Check-then-act. This race condition happens when two processes check a value on which they will take each take an external action. The processes both check the value, but only one process can take the value with it. The later-occurring process will read the value as null. This results in a potentially out-of-date or unavailable observation being used to determine what the program will do next. For example, if a map application runs two processes simultaneously that require the same location data, one will take the value first so the other can't use it. The later process reads the data as null.
What security vulnerabilities do race conditions cause?
A program that is designed to handle tasks in a specific sequence can experience security issues if it is asked to perform two or more operations simultaneously. A threat actor can take advantage of the time lapse between when the service is initiated and when a security control takes effect in order to create a deadlock or thread block situation.
A deadlock vulnerability is a severe form of a denial-of-service vulnerability. It can be made to occur when two or more threads must wait for one another to acquire or release a lock in a circular chain. This situation results in deadlock, where the entire software system comes to a halt because such locks can never be acquired or released if the chain is circular.
Thread block can also dramatically impact application performance. In this type of concurrency defect, one thread calls a long-running operation while holding a lock and preventing the progress of other threads.
How to identify race conditions
Detecting and identifying race conditions is considered difficult. They are a semantic problem that can arise from many possible flaws in code. It's best to design code in a way that prevents these problems from the start.
Programmers use dynamic and static analysis tools to identify race conditions. Static testing tools scan a program without running it. However, they produce many false reports. Dynamic analysis tools have fewer false reports, but they may not catch race conditions that aren't executed directly within the program.
Race conditions are sometimes produced by data races, which occur when two threads concurrently target the same memory location and at least one is a write operation. Data races are easier to detect than race conditions because specific conditions are required for them to occur. Tools, such as the Go Project's Data Race Detector, monitor for data race situations. Race conditions are more closely tied to application semantics and pose broader problems.
How do you prevent race conditions?
Two ways programmers can prevent race conditions in operating systems and other software include:
- Avoid shared states. This means reviewing code to ensure when shared resources are part of a system or process, atomic operations are in place that run independently of other processes and locking is used to enforce the atomic operation of critical sections of code. Immutable objects can also be used that cannot be altered once created.
- Use thread synchronization. Here, a given part of the program can only execute one thread at a time.
Preventing race conditions with other types of technology is also possible:
Storage and memory
The serialization of memory or storage access will also prevent race conditions. This means if read and write commands are received close together, the read command is executed and completed first by default.
Networking
In a network, a race condition may occur if two users try to access a channel at the same instant and neither computer receives notification the channel is occupied before the system grants access. Statistically, this kind of situation occurs mostly in networks with long lag times, such as those that use geostationary satellites.
To prevent such a race condition, a priority scheme must be devised to give one user exclusive access. For example, the subscriber whose username or number begins with the earlier letter of the alphabet or the lower numeral may get priority when two subscribers attempt to access the system within a prescribed increment of time.
The takeaway
Race conditions show up in several ways in software, storage, memory and networking. Proactively monitoring for them and preventing them is a critical part of software and technology design and development.
Preventing race conditions is particularly important because hackers can take advantage of race-condition vulnerabilities to gain unauthorized access to networks. One notable example of a race condition-based exploit is called Dirty Cow, which exploits a flaw in a Linux kernel's memory subsystem to create a race condition where the attacker gains write privileges for read-only memory mappings.