parallel file system

A parallel file system is a software component designed to store data across multiple networked servers and to facilitate high-performance access through simultaneous, coordinated input/output operations (IOPS) between clients and storage nodes.
A parallel file system breaks up a data set and distributes, or stripes, the blocks to multiple storage drives, which can be located in local and/or remote servers. Users do not need to know the physical location of the data blocks to retrieve a file. The system uses a global namespace to facilitate data access. Parallel file systems often use a metadata server to store information about the data, such as the file name, location and owner.
A parallel file system reads and writes data to distributed storage devices using multiple I/O paths concurrently, as part of one or more processes of a computer program. The coordinated use of multiple I/O paths can provide a significant performance benefit, especially when streaming workloads that involve a large number of clients.
Capacity and bandwidth can be scaled to accommodate enormous quantities of data. Storage features may include high availability, mirroring, replication and snapshots.
Common use cases of parallel file systems
Parallel file systems historically have targeted high-performance computing (HPC) environments that require access to large files, massive quantities of data or simultaneous access from multiple compute servers. Applications include climate modeling, computer-aided engineering, exploratory data analysis, financial modeling, genomic sequencing, machine learning and artificial intelligence, seismic processing, video editing and visual effects rendering.
Users of parallel file systems span national laboratories, government agencies and universities, as well as industries such as financial services, life sciences, manufacturing, media and entertainment, and oil and gas.
Parallel file system implementations may span thousands of server nodes and manage petabytes or exabytes of data. Users typically deploy high-speed networking such as fast Ethernet, InfiniBand, or proprietary technologies to optimize the I/O path and enable greater bandwidth.
Parallel file system vs. distributed file system
A parallel file system is a type of distributed file system. Both distributed and parallel file systems can spread data across multiple storage servers, scale to accommodate petabytes of data, and support high bandwidth.
Distributed file systems typically support a shared global namespace, as parallel file systems do. But with a distributed file system, all client systems accessing a given portion of the namespace generally go through the same storage node to access the data and metadata, even if parts of the file are stored on other servers. With a parallel file system, the client systems have direct access to all of the storage nodes for data transfer without having to go through a single coordinating server.
Additional distinctions may include:
- A distributed file system generally uses a standard network file access protocol, such as NFS or SMB, to access a storage server. A parallel file system generally requires the installation of client-based software drivers to access the shared storage via high-speed networks such as Ethernet, InfiniBand, and OmniPath.
- A distributed file system often stores a file on a single storage node, whereas a parallel file system generally breaks up the file and stripes the data blocks across multiple storage nodes.
- Distributed file system deployments can store data on the application servers or centralized servers, while typical parallel file system deployments separate the compute and storage servers for performance reasons.
- Distributed file systems tend to target loosely coupled, data-heavy applications or active archives. Parallel file systems focus on high-performance workloads that can benefit from coordinated I/O access and significant bandwidth.
- Distributed file systems often use techniques such as three-way replication or erasure coding to provide fault tolerance in the software, whereas many parallel file systems run on shared storage.
Examples of parallel file systems
Two of the most prominent examples of parallel file systems are IBM's Spectrum Scale, built upon its General Parallel File System (GPFS), and the open source Lustre file system.
IBM’s GPFS/Spectrum Scale is a block-based parallel file system that uses blocks of tunable width and dynamic metadata for information distribution. Spectrum Scale supports native AIX, Linux and Windows clients, and offers features such as snapshots, encryption and built-in data policy management.
Lustre is an object-based parallel file system with file regions that can vary in length and static metadata for information distribution. Lustre supports a range of Linux distributions and offers features such as scaling of metadata servers, an online consistency checker and quality of service.
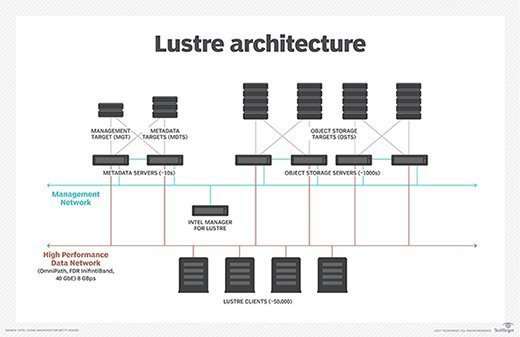
Additional examples of parallel file systems include:
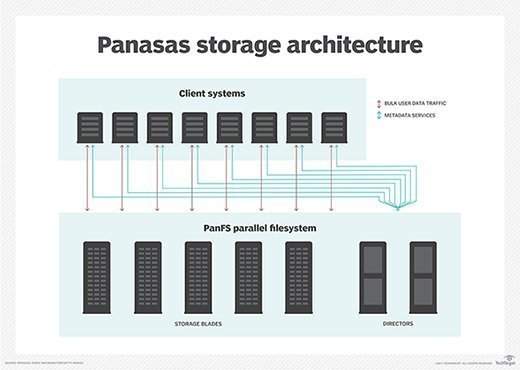
Panasas PanFS. PanFS is a parallel file system developed by Panasas Inc. It uses erasure codes to layer files over an object-based storage pool and dynamic metadata for information distribution. PanFS supports native Linux and macOS clients, and is sold in a pre-configured, scale-out appliance form factor.
Parallel Virtual File System. PVFS is an Open Source file system for Linux-based clusters developed and supported by the Parallel Architecture Research Laboratory at Clemson University and the Mathematics and Computer Science Division at Argonne National Laboratory. PVFS is based on Vesta, which was developed at IBM’s T.J. Watson Research Center.
OrangeFS. Open source parallel file system targeting parallel computation environments; branch of PVFS created by Clemson developers to support a broader range of use cases and features.






