erasure coding

Erasure coding (EC) is a method of data protection in which data is broken into fragments, expanded and encoded with redundant data pieces and stored across a set of different locations or storage media.
If a drive fails or data becomes corrupted, the data can be reconstructed from the segments stored on the other drives. In this way, EC can help increase data redundancy, without the overhead or limitations that come with different implementations of RAID.
How does erasure coding work?
Erasure coding works by splitting a unit of data, such as a file or object, into multiple fragments (data blocks) and then creating additional fragments (parity blocks) that can be used for data recovery. For each parity fragment, the EC algorithm calculates the parity's value based on the original data fragments. The data and parity fragments are stored across multiple drives to protect against data loss in case a drive fails or data becomes corrupted on one of the drives. If such an event occurs, the parity fragments can be used to rebuild the data unit without experiencing data loss.
For example, a storage system might use a 5+2 encoding configuration to distribute data across multiple physical drives. In this configuration, the EC algorithm breaks each data unit into five data fragments and then adds two parity fragments, which are calculated from the original data. Each fragment is stored on a different physical drive. As a result, the storage system must include at least seven drives.
This article is part of
What is data protection and why is it important?
In a 5+2 configuration, the parity data consumes 29% of raw capacity. The configuration can also tolerate up to two disk failures, whether the disks contain data fragments or parity fragments. However, EC is flexible enough to support a wide range of configurations. For example, a 17+3 encoding would split each data unit into 17 segments and then add three parity segments. Although this configuration requires at least 20 physical drives, it can support up to three simultaneous disk failures, while reducing the parity overhead to less than 18%.
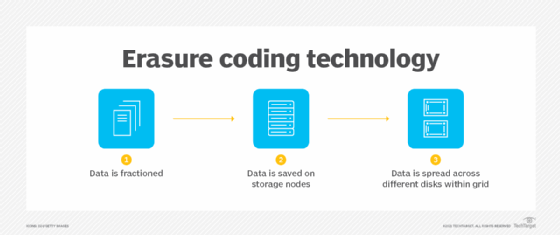
Erasure coding makes it possible to protect data without having to fully replicate it because the data can be reconstructed from parity fragments. For instance, in a simple 2+1 configuration, a data unit is split into two segments, with one parity fragment added for protection. If an application tries to retrieve data from either of the data segments and those segments are available, the operation proceeds as normal, even if the parity segment is unavailable.
However, if the first data fragment is available but the second data fragment isn't, or vice versa, data is read from the first data fragment and the parity fragment. Together these two fragments are used to reconstruct the data that was in the second fragment, making it possible to continue data operations while the disk is being rebuilt.
Erasure coding vs. RAID
Erasure codes, also known as forward error correction codes, were developed more than 50 years ago to help detect and correct errors in data transmissions. The technology has since been adopted to storage to help protect data in the event of drive failure or data corruption. More recently, EC has been gaining popularity for use with large object-based data sets, particularly those in the cloud. As data sets continue to grow and object storage is more widely implemented, EC is becoming an increasingly viable alternative to RAID.
RAID
RAID relies on two primary mechanisms for protecting data: mirroring and striping with parity. Mirroring is one of the most basic forms of data protection. When used alone, it's referred to as RAID 1. In this configuration, multiple copies of the data are stored on two or more drives. If one drive fails, the data can be retrieved from one of the other drives, without interruption to service. Mirroring is easy to implement and maintain, but it uses a large amount of storage resources, just like any form of replication.
Striping with parity, referred to as RAID 5, stripes data across multiple hard disks and adds parity blocks to protect the data. If a drive fails, the missing data can be reconstructed using the data on the other disks. However, RAID 5 can support only one disk failure at a time. For this reason, some vendors offer RAID 6 storage systems, which can handle up to two simultaneous disk fails. Different RAID configurations can also be combined, as in RAID 10, which uses disk mirroring and data striping without parity to protect data.
The various RAID configurations have been integral to data center operations for many years because the technology is well understood and has proven a reliable form of data protection for a wide range of workloads. However, RAID comes with significant challenges. For example, mirroring is inefficient when it comes to resource utilization, and striping with parity can protect against only two simultaneous disk failures at best.
Another issue with RAID is related to capacity. As disk drives become larger, it takes much more time to rebuild a drive if it should fail. Not only can this affect application performance, it can also increase the risk of losing data. For example, if a drive fails in a RAID 5 configuration, it might take days to rebuild that drive, leaving the storage array in a vulnerable position until the rebuild is complete. An incapacitated disk can also affect application performance.
Erasure coding
In some cases, erasure coding can be used in place of RAID to address its limitations. Erasure coding can exceed RAID 6 in terms of the number of failed drives that can be tolerated, increasing the level of fault tolerance. In a 10+6 erasure coding configuration, 16 data and polarity segments are spread across 16 drives, making it possible to handle up to six simultaneous drive failures.
Erasure coding is also much more flexible than RAID, whose configurations are fairly rigid. With EC, organizations can implement a storage system to meet their specific data protection requirements. In addition, EC can reduce the amount of time it takes to rebuild a disk that has failed, depending on the configuration and number of disks.
Despite these benefits, EC has a serious drawback: its effect on performance. Erasure coding is a processing-intensive operation. The EC algorithm must run against all data written to storage, and the data and parity segments must be written across all participating disks. If a disk fails, rebuild operations put an even greater strain on CPU resources because the data must be reconstructed on the fly. RAID configurations, whether mirroring or striping with parity, have much less of an effect on performance and can often improve it.
Why is erasure coding useful?
Major cloud storage services such as Amazon Simple Storage Service (S3), Microsoft Azure and Google Cloud use erasure coding extensively to protect their vast stores of data. Erasure coding has proven especially beneficial for protecting object-based storage systems, as well as distributed systems, making it well suited to cloud storage services. That said, erasure coding has also been making its way into on-premises object storage systems, such as the Dell EMC Elastic Cloud Storage (ECS) object storage platform.
Erasure coding can be useful with large quantities of data and any applications or systems that must tolerate failures, such as disk array systems, data grids, distributed storage applications, object stores and archival storage. Most of today's use cases revolve around large data sets for which RAID isn't a practical option. To support EC, the infrastructure must be able to deliver the necessary performance, which is why its predominant use case has been with major cloud services.
Erasure coding is often recommended for storage such as backups or archive -- the types of data sets that are fairly static and not write-intensive. That said, erasure coding is finding its way into a variety of systems trying to avoid the high costs of replication. For example, many Hadoop Distributed File System (HDFS) implementations now use EC to reduce the overhead associated with storing redundant data across data nodes. In addition, object storage platforms such as Hitachi Content Platform now support erasure coding for protecting data.
What are the benefits of erasure coding?
Although RAID can still be a useful tool for data protection, EC offers several important benefits that should be considered when planning data storage:
- Better resource utilization. Replication techniques such as RAID 1 mirroring use a high percentage of storage capacity for data copies. Erasure coding can significantly reduce storage consumption, while still protecting data. The exact amount of capacity saving will depend on the encoding configuration, but whatever it is, it will still translate to greater storage efficiency and lower storage costs.
- Lower risk of data loss. When a RAID array is made up of high-capacity disks, rebuilding a failed drive can take an extremely long time, which increases the risk of data loss should another drive fail before the first one can be rebuilt. Erasure coding can handle many more simultaneous disk failures, depending on the encoding configuration, which means that there is a lower risk of data loss if a drive goes down.
- Greater flexibility. RAID tends to be limited to fairly fixed configurations. Although vendors can implement proprietary RAID configurations, most RAID implementations are fairly standard. Erasure coding provides far more flexibility. Organizations can choose the data-to-parity ratio that best fits their specific workloads and storage systems.
- Greater durability. Erasure coding enables an organization to configure a storage system that offers a high degree of availability and durability. For example, Amazon S3 is designed for 99.999999999% object durability across multiple Availability Zones. Unlike RAID 6, which can sustain only two simultaneous disk failures, an EC-based system can be configured to handle substantially more.
When planning their storage strategies, organizations must consider several factors, including how to protect against data loss and provide disaster recovery. Straightforward replication is one approach and RAID is another. Erasure coding is yet one more.
Each strategy comes with advantages and disadvantages. However, with the growing amount of data and continued move to object storage, EC is destined to gain momentum. Erasure coding enables organizations to meet their scalability needs and still protect their data, without incurring the high costs of full replication. Even so, no technology can flourish without adapting to industry changes, and the EC in service today could look much different five years down the road.







