RAID 0 (disk striping)
What is RAID 0 (disk striping)?
RAID 0 (disk striping) is the process of dividing a body of data into blocks and spreading the data blocks across multiple storage devices, such as hard disks or solid-state drives (SSDs), in a redundant array of independent disks group.
A stripe consists of the data divided across the set of hard disks or SSDs, and a striped unit refers to the data slice on an individual drive.
How RAID 0 works
Because striping spreads data across more physical drives, multiple disks can access the contents of a file, enabling writes and reads to be completed more quickly. However, unlike other RAID levels, RAID 0 does not have parity. Disk striping without parity data does not have redundancy or fault tolerance. That means, if a drive fails, all data on that drive is lost.
Storage systems perform disk striping in different ways. A system may stripe data at the byte, block or partition level, or it can stripe data across all or some of the disks in a cluster. For instance, a storage system with 10 hard disks might stripe a 64 KB block on the first, second, third, fourth and fifth disks and then start over again at the first disk. Another system might stripe 1 megabyte (MB) of data on each of its 10 disks before returning to the first disk to repeat the process.
RAID 0 is best for storage that is noncritical but requires high-speed reads and writes. Caching live streaming video and video editing are common uses for RAID 0 due to speed and performance. Disk striping without data redundancy may be used for temporary data, scratch space or situations where a master copy of the data is easily recoverable from another storage device.
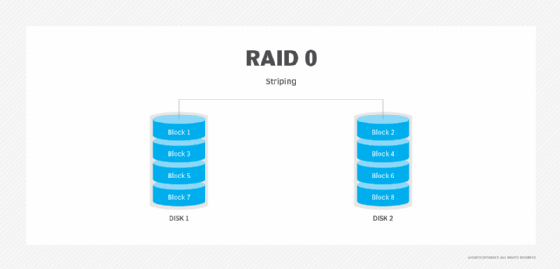
Some RAID levels use disk striping to distribute and store data across multiple physical drives. Disk striping is synonymous with RAID 0 and spreads the data across all the disk drives in a RAID group without parity data.
Advantages and disadvantages of RAID 0
The main advantage of RAID 0 and disk striping is improved performance. For example, striping data across three hard disks would provide three times the bandwidth of a single drive. If each drive runs at 200 IOPS, disk striping would make available up to 600 IOPS for data reads and writes.
RAID 0 avoids overhead by not using parity data and by using all of the data storage capacity available. Along with being easy to implement, RAID 0 has the lowest cost of all the RAID levels and all hardware controllers support it.
The disadvantage of disk striping is low resiliency. RAID 0 does not use data redundancy, so the failure of any physical drive in the striped disk set results in the loss of the data on the striped unit and, consequently, the loss of the entire data set stored across the set of striped hard disks. It should not be used for mission-critical storage.
Disk striping with parity
RAID 0 writes data without parity used in other types of RAID. For instance, RAID 3 and RAID 4 use a dedicated parity disk, while RAID 5 distributes its parity information across drives. RAID 6 uses two drives for parity and protects against two drive failures. Data protection can be extended beyond two storage device failures using erasure coding.
Disk striping with RAID provides data redundancy and reliability. Parity data is commonly calculated by using the binary exclusive function stored on a physical drive in the RAID set. If a storage drive in the striped RAID set fails, the data is recoverable from the remaining drives and the parity stripe.
For a data set with n drives, the data might be striped on drives n through n minus 1, and the nth drive would be reserved for parity. For example, in a RAID set with 10 drives, data could be striped to nine drives, and the 10th drive would be used for parity.
One disadvantage of disk striping with parity is the performance penalty for small random writes, as the system accesses all the stripe units in the striped RAID set.
Disk striping and disk mirroring
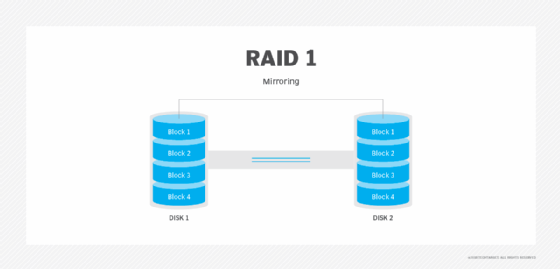
In a RAID array, disk mirroring -- also known as RAID 1 -- duplicates data from one hard drive to another. This creates data redundancy, which will aid in recovery if an array fails. Like striping, disk mirroring provides high performance. The mirroring in RAID 1 also has the benefit of providing high availability and rapid recovery but cannot match the speedy reads and writes of RAID 0.
If there are an even number of hard disk drives, disk striping can be combined with disk mirroring to speed up performance and expand capacity by striping data across multiple sets of mirrored drives. This combination is also called RAID 10, or RAID 1+0.
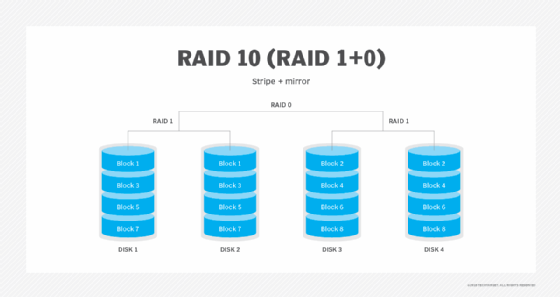
The disadvantage of disk striping with mirroring is the 50% overhead inherent in using half the capacity to make an exact copy of the data for protection.
RAID 0 vs. RAID 5, JBOD and SSDs
RAID 5 is the most common version of RAID used today and can be combined with RAID 0 or used as an alternative. RAID 5 can provide more economical redundancy and stripes data across hard disks while distributing parity. It provides more usable storage than RAID 1 but has the disadvantage of reduced performance due to rebuilds.
Outside of other RAID levels, alternatives to disk striping can include JBOD (just a bunch of disks) and SSDs. Like RAID 0, JBOD is composed of multiple physical drives. While the drives in RAID arrays need to be of similar capacity, those in JBOD arrays can vary.

Like RAID 0, a JBOD array uses all available storage capacity, not reserving any for redundancy. This makes a JBOD array a cost-effective alternative to many RAID arrays. However, JBOD arrays don't come close to the speed of RAID with reads and writes, especially not the accelerated reads and writes of RAID 0.

SSDs are growing in popularity as prices go down, thanks to their rapid speeds. Of all the RAID levels, RAID 0 comes the closest to the read and write speeds of SSDs. RAID 0 does have limitations, however, thanks to RAID controller throughput and general processing speeds. While closer than other RAID configurations, RAID 0 cannot match the speed and performance provided by an SSD.
However, while costs are dropping, an SSD remains significantly more expensive than an economical RAID array, so the decision between them ultimately comes down to prioritizing speed and performance vs. costs.
Editor's note: This article was revised in 2023 by TechTarget editors to improve the reader experience.







