bad block
A bad block is an area of storage media that is no longer reliable for storing and retrieving data because it has been physically damaged or corrupted. Bad blocks are also referred to as bad sectors.
There are two types of bad blocks: A physical, or hard, bad block comes from damage to the storage medium. A soft, or logical, bad block occurs when the operating system (OS) is unable to read data from a sector. Examples of a soft bad block include when the cyclic redundancy check (CRC), or error correction code (ECC), for a particular storage block does not match the data read by the disk.
On magnetic hard disk drives (HDDs), bad blocks can happen when a location on the recording surface is defective or damaged. On NAND flash drives, blocks can become worn from use, making them unreliable or unusable after a certain number of write and erase cycles.
Causes
Storage drives can ship from the factory with defective blocks that originated in the manufacturing process. Before the device leaves the factory, these bad blocks are marked as defective and remapped to the drive's extra memory cells.
A bad block can also result from physical damage to a device that makes it impossible for the OS to access data. On HDDs, mishaps, such as dropping a laptop, can cause the drive head to damage the platter. Dust and natural wear can also damage HDDs.
Damage to a solid-state drive (SSD) can occur when a memory transistor fails. Storage cells can also become unreliable over time, as the NAND flash substrate in a cell becomes unusable after a certain number of program-erase cycles.
The erase process on an SSD requires sending a large electrical charge through the flash cell. Over time, this degrades the oxide layer that separates the floating gate transistors from the flash memory silicon substrate and the bit error rates increase. The drive's controller can use error detection and correction mechanisms to fix these errors. However, at some point, the errors can outstrip the controller's ability to correct them and the cell can become unreliable.
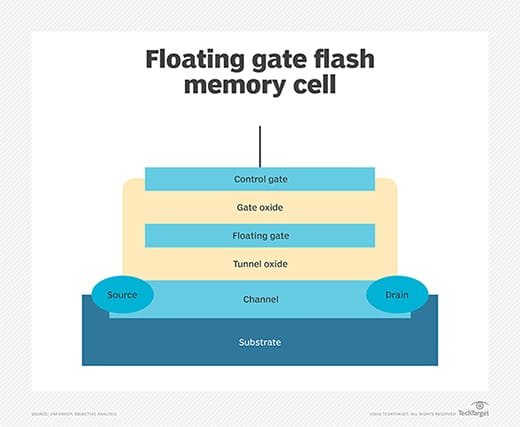
Soft bad sectors are caused by software problems. For instance, if a computer unexpectedly shuts down, the hard drive could turn off in the middle of writing to a block. In this case, the block could contain data that doesn't match its CRC error correction code and would be identified as a bad sector.
What bad blocks do
When a block is damaged or corrupted, it can make the data stored there inaccessible. If operating system or application files are stored in a damaged block, that can cause OS issues or result in an application failing to run. As the number of bad blocks on a disk increases, they can diminish the drive's capacity and performance and eventually cause hardware failure.
Disk utility software, such as CHKDSK on Microsoft Windows systems or badblocks on Linux systems, can scan storage media and mark the failed sectors so that the OS doesn't use them. The firmware on an HDD controller can also identify and mark a bad block as unusable. This usually happens when a block is being overwritten with new data. The controller automatically remaps bad blocks to a different sector. Once it is identified as bad, that sector is not used in future operations.
Bad blocks that are identified during the post-manufacturing testing of a drive are listed on what is called the P-List, short for permanent or primary defect list. Bad blocks found after the drive is in use, caused by physical damage or deterioration of the recording surface, are recorded on the G-List, short for growing list.
When a NAND flash drive identifies a bad block, it's recorded in the device's Bad Block Table (BBT). Before reading from or writing to a NAND device, the controller checks the device's BBT to avoid bad blocks. Flash drives use two kinds of BBTs: NAND-resident ones are retained across system boots, and RAM-resident BBTs are recreated each time the system is booted.
Management
The best way to fix an HDD file that has been affected by a bad block is to write over the original file. This will cause the hard disk to remap the bad block or fix the CRC or data.
Bad block management is critical to improving NAND flash drive reliability and endurance. Unlike magnetic storage media, flash can't be overwritten at the byte level; all changes must be written to a new block and the data in the original block must be marked for deletion.
Once a flash drive fills up, the controller must start clearing out blocks marked for deletion before it can write new data. To do this, it consolidates good data by copying it to a new block. This process requires extra writes to consolidate the good data and results in write amplification where the number of actual writes exceeds the number of writes requested. Write amplification can decrease the performance and life span of a flash drive.
Flash vendors use a number of techniques to control write amplification. One, known as garbage collection, involves proactively consolidating data by freeing up blocks that were written to previously. Done properly, these reallocated sectors can reduce the need to erase entire blocks of data for every write operation.
Storage analyst Eric Slack discusses how NAND flash storage degrades over time and what's being done to increase the endurance of solid-state drives.
Vendors also use data reduction technologies, such as compression and deduplication, to minimize the amount of data being written and erased on a drive. In addition, an SSD's interface can help decrease write amplification. Serial ATA's TRIM and SAS's UNMAP commands identify data blocks no longer in use that can be wiped out. This approach minimizes garbage collection and frees up space on the drive, resulting in better performance.
To extend the life of a solid-state device, the controller software that manages a NAND device can implement a wear-leveling algorithm to distribute program-erase cycles (P/E cycles) evenly across a drive and ensure that no block has excessive use compared with other blocks. With wear leveling, the flash device remaps storage blocks each time a write occurs. This approach ensures that write cycles are spread across all of the memory cells and no one block is written to more than others, reducing the chance that blocks will prematurely fail.
To support operations such as wear leveling and garbage collection, vendors overprovision flash capacity on a drive. That way, a drive has an inventory of cells available to support write operations, improve drive performance and replace cells that wear out.







