storage capacity planning
What is storage capacity planning?
Storage capacity planning is the practice of assessing current data storage needs and forecasting future storage requirements. The goal is to purchase just enough disk space to meet the needs of users and applications.
Simply stated, storage capacity planning ensures that storage resources are available when needed. When planning for storage capacity, administrators must look at how storage is allocated across all elements of the storage infrastructure. This includes systems, files, databases and other resources the organization uses.
Effective capacity planning lets data storage administrators buy only what they need when they need it. As a result, they save money on storage resources that would otherwise go unused and can better allocate their storage budgets.
How storage capacity planning works
The most popular way to determine storage requirements is to deploy storage capacity planning tools. They analyze storage systems and generate reports on available data storage capacity and performance.
Other ways to do capacity planning include the following two methods:
- capturing storage data, posting it on spreadsheets and then performing analyses of previous and current usage trends; and
- implementing a chargeback process that tracks storage use by groups or departments.
Both approaches are time-consuming, which is why automated storage capacity planning applications have become popular.
Benefits of storage capacity planning
Effective capacity planning provides several benefits to businesses, such as the following:
- Planning. It lets data storage administrators plan and schedule disk purchases based on projected needs.
- Availability. It ensures storage resources are available when they are needed.
- Cost. It lets organizations buy only the storage they need and take advantage of changes in disk storage pricing.
- Timing. It can identify the best time to make changes in storage resources, using historical data, current performance data and metrics that look at future requirements.
Key storage planning factors to consider
Factors to consider in capacity planning include the potential data storage requirements of future projects. The storage architecture used should also be considered. For example, tiered storage allows less frequently accessed items to be moved to a lower and less costly type of storage, freeing faster and more expensive tiers for applications that need it.
Storage administrators must capture knowledge of business activities that may affect storage requirements. That information must be factored into storage consumption and data growth planning.
For instance, an impending merger or acquisition could have impact storage capacity needs. It is essential that storage administrators work closely with business leaders to get insight on and estimates of storage needs well in advance of any changes. If an organization uses both on-site and remote, cloud-based storage, all those resources may need to be reviewed and updated for future requirements.
How to manage storage capacity
It is not enough to simply look at storage capacity planning as adding more storage. It may be possible to reduce storage needs using techniques such as these:
- data deduplication, where extra copies of the same file are eliminated reducing the amount of storage capacity needed;
- file compression, which can cut the space needed to store files and images;
- thin provisioning, which lets storage administrators virtually dedicate storage and allocate it only when needed; and
- storage virtualization, an approach that allows physical storage to be pooled and managed from one storage device.
How do storage capacity planning tools work?
Specialized systems are available that capture data on the health of an organization's storage infrastructure. Sensors embedded in storage devices and network resources capture storage data. Such data includes storage capacity metrics, like the amount of space available on a device or how quickly data moves between systems and users.
Collecting this data can help identify issues with storage consumption, growth and performance bottlenecks. Once identified, they can be addressed before users are affected.
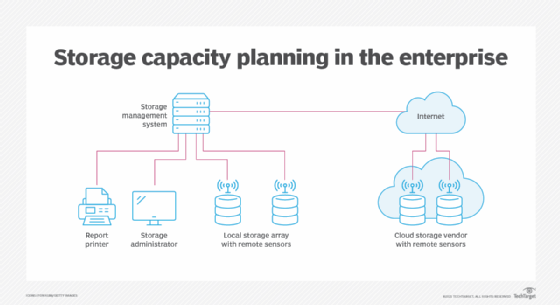
Capacity planning tools provide several important outputs:
- Reports on elements of storage health and performance. These can include information tracking dynamic relationships among virtual machines, logical unit numbers, storage pools and arrays. Analyzing this sort of trend data may help identify root causes of capacity issues.
- Custom reports. These can be produced for presentation to management, auditors, business unit leaders and other interested parties. They can provide real-time data on capacity issues of various storage systems.
- Dashboards. These provide real-time views of the storage infrastructure and metrics such as data growth.
Learn more about effectively managing data storage and the critical role of capacity management.






