
Pavel Ignatov - Fotolia
Watch out for these 5 hybrid cloud security challenges
Protect your hybrid cloud environment against these five common security vulnerabilities. Avoid the risks with established strategies and public cloud tools.

Many companies that migrate workloads to the cloud still need to retain their data centers due to strict compliance requirements or heavy investment in bare metal infrastructure. In cases like these, businesses usually opt for a hybrid cloud model.
However, this model brings additional security complexities to the table. In this article, we'll look at five common hybrid cloud security challenges and the tools and strategies organizations can use to overcome them.
1. Data transfer within the hybrid cloud
A hybrid cloud architecture typically involves infrastructure from two different providers -- a public cloud provider and a private cloud provider. These environments are often separated by the public internet. This poses a security concern, so it is up to you to make sure your data stays safe in transit.
Encrypt all traffic to overcome this hybrid cloud security challenge. Enforce the latest encryption standards and ciphers, but define your own requirements based on your specific needs.
The major cloud vendors provide Transport Layer Security or client-side encryption to ensure the safety of your data.
2. Authentication and authorization
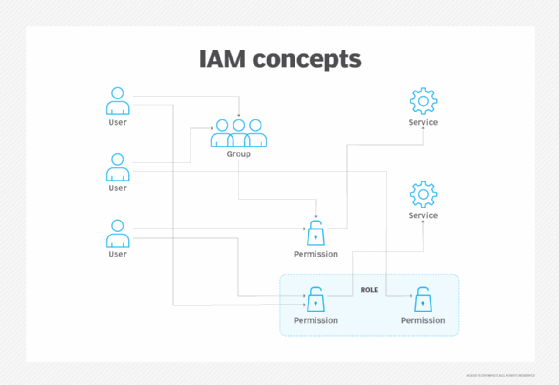
Authentication and authorization are important in any business, but they require extra attention when dealing with the complexities of hybrid cloud security. You must evaluate how your data will be accessed on premises and in the public cloud. To secure these accounts, use identity and access management tools to set up identity federation.
Consider single sign-on tools to centralize hybrid cloud access management, especially if your environment uses multiple cloud and on-premises accounts. You can opt for a public cloud managed tool, such as AWS Single Sign-On or Microsoft Azure Active Directory Seamless Single Sign-On, or look into popular third-party products like Okta.
3. The skills gap
When you implement an unfamiliar technology, anyone in your company with any kind of access to that technology is a security risk. Employees rarely act maliciously, but you can certainly expect them to make mistakes.
If your users are new to public cloud, they'll need to adapt to the software deployment models and how they differ from more traditional on-premises approaches. For example, workloads are secured differently on AWS, Azure or Google Cloud than they are in your private data center.
In addition, developers might be drawn to services that automate deployments across a hybrid cloud. This includes infrastructure-as-code tools such as Terraform, version control systems like Git and CI/CD tools like TeamCity and Jenkins.
To avoid security risks due to human error, ensure permissions are given on a least-privilege basis. The tools themselves should have limited access, and only allow employees to use them for specific, role-based functions.
Also, dedicate resources to employee training. Each person who is working with the cloud must, at the very least, have an understanding of the components and services they work with on a regular basis. Use official public cloud training and certifications, free or paid online courses, or some other tool to educate your employees.
4. Networking that spans the hybrid cloud
Networking is the base upon which your entire infrastructure sits. With a hybrid cloud, you have to worry about networking for each environment, as well as the network connections that glue those environments together. There's no room for mistakes here, so it's imperative that you utilize public cloud providers' networking tools and services for this purpose.
For example, if you use AWS, set up a site-to-site VPN between your data center and AWS, which connects directly to your Amazon VPC. You can also use services like AWS Direct Connect, Azure ExpressRoute and Google Cloud Interconnect. These offerings provide secure, dedicated network connections to your public cloud environment and also reduce the cost of data transfers.
5. Compliance concerns
Hybrid clouds pose significant compliance challenges around data movement. These challenges, such as adherence to data sovereignty laws and GDPR compliance, hold true even in a small and simple hybrid environment. In highly regulated sectors such as healthcare, government and finance, a small mistake can lead to serious fines or even lawsuits.
To ensure proper compliance, start by evaluating each individual environment. Then, look at the hybrid cloud as a whole for overall security. There is no room for mistakes, so you need to be mindful of these considerations at every step as you build your hybrid cloud. It's much harder to fix a compliance problem after the fact.







