Podcasts
-

Storage Spaces Direct a key option in Windows Server 2016 features
Windows Server 2016 includes new and updated capabilities with Storage Spaces, Storage Replica, Storage Quality of Service, data deduplication and Resilient File System.
-
A tiered storage model is different from caching
In this podcast, Evaluator Group strategist Randy Kerns looks in-depth at today's tiered storage model, including how it differs from flash caching.
-
How NAND flash degrades and what vendors do to increase SSD endurance
Storage Switzerland senior analyst Eric Slack digs into the technical aspects of SSD cell degradation and how vendors are increasing SSD endurance.
-
Erasure coding tradeoffs include additional storage, disk update needs
Erasure coding tradeoffs include requirement for additional data storage, need to update extra disks for redundancy purposes, UC professor cautions.
-
Erasure coding brings trade-off of resilience vs. performance
IT's decision on using erasure coding in storage rests on data importance, durability more than amount of data, says storage consultant Marc Staimer.
-
Wikibon CTO: Erasure coding can help reduce data backup costs
Erasure coding can help reduce the data needed for backups and lower the cost of backup and recovery over the traditional approach, Wikibon CTO says.
-
Data durability guarantees shouldn't be big concern with cloud storage
Data durability guarantees of cloud storage providers shouldn't be a big point of concern for customers; they're too tough to measure and enforce.
-
How to access cloud storage: Transfer, retrieval not so simple
Public cloud data access is straightforward, but data transfer to another provider or in-house could leave users on their own, analyst warns.
-
RHEV 3.1 storage: Functionality and considerations
Virtualization expert Sander van Vugt explains how RHEV storage works and discusses some of the new storage features in version 3.1.
-
What you need to know about improving iSCSI performance
Storage expert Dennis Martin discusses how technologies like Data Center Bridging, CHAP, IPsec and iSCSI offload adapters affect iSCSI performance.
-
Third-party tools help with VMware monitoring for storage
Third-party tools provide a single interface to help IT shops monitor the performance of storage, servers and network traffic in VMware environments.
-
What you need to know about SMB SANs
Marc Staimer discusses what to look for in an SMB SANs this Q&A and recent developments in SMB SAN technology.
-

EDRM: Best practices when preparing for an e-discovery request
We list the nine stages of the Electronic Discovery Reference Model (EDRM), and tell you why the preservation and collection stage is so important to data storage pros.
Photo Stories
-
Speeds of storage networking technologies rise as flash use spikes
-

Keep tabs on the following data storage startup vendors in 2017
-

Five ways VDI technology is affected by storage
-
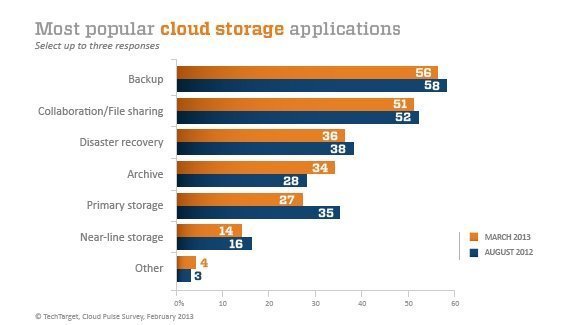
Survey finds cloud storage implementation growing but cautious
-

Data storage companies focus on flash M&A potential