tiered storage
What is tiered storage?
Tiered storage is a method for assigning different categories of data to various types of storage media to reduce overall storage costs and improve the performance and availability of mission-critical applications. A tiered storage architecture categorizes data hierarchically based on its business value, with data ranked by how often it's accessed by users and applications. The data is then assigned to specific storage tiers that are defined by their performance, availability and media costs.
Generally, the most important data is served from the fastest storage media, which is typically the most expensive. In a basic configuration, mission-critical data might be assigned to a high-performing tier that consists of flash solid-state drives (SSDs) and Intel Optane memory modules, while less critical data is written to a second tier made up only of hard disk drives (HDDs). A third tier might then be used for archiving data that needs to be kept indefinitely, with the data stored on tape drives or cloud storage platforms.
Tiering is one link in a chain of activities governed by information lifecycle management (ILM).
What is the history of tiered storage?
IBM pioneered the multi-tiered storage architecture for use on its mainframe computers. When tiered storage was first conceived, primary production data was manually placed on varying configurations of serial-attached SCSI (SAS) and Serial Advanced Technology Attachment (SATA) hard drives. Data was written to blocks on disks using techniques such as short stroking and striping across a redundant array of independent disks (RAID).
This resulted in tiers of storage with varying capacity, cost and performance characteristics, which made it possible to address different storage requirements within a single mainframe. To provide further flexibility, an additional tier of tape libraries sat behind the other media to support warm data or to provide a deep archive for cold data.
The rise of hierarchical storage management (HSM) helped reduce the manual process of storage tiering. HSM introduced software-based automation, which shuttles the data dynamically between different storage systems, drive types or RAID groups in real time, in ways that are largely transparent to the user.
What is multi-tiered storage?
A tiered approach to data management utilizes different types of storage media to create multiple tiers for accommodating different types of data. The exact approach that organizations take to tiering depends on their specific storage, data and application requirements. Today's IT teams might support anywhere between two and five tiers, sometimes even more.
To a large degree, the number of tiers will depend on how an organization classifies its data. For example, business data is often grouped into one of four categories: mission critical, hot data, warm data and cold data. Based on these categories, an organization might implement four storage tiers -- Tier 0, Tier 1, Tier 2, Tier 3 -- with Tier 0 supporting mission-critical workloads and Tier 3 storing cold data.
Organizations aren't locked into this structure -- they might deploy more tiers or fewer tiers -- but this approach represents the basic principles that go into a multi-tiered storage architecture.
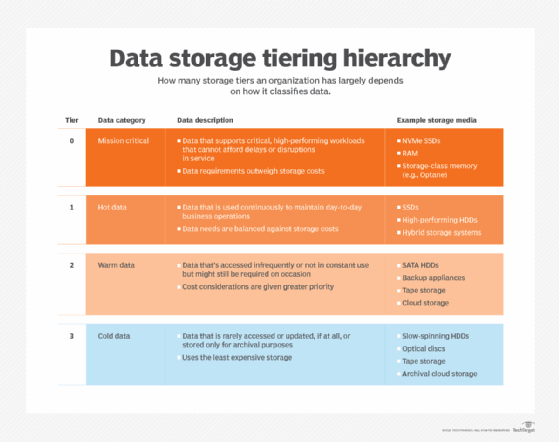
Companies can deviate from this structure in multiple ways. For example, they might break Tier 1 or Tier 2 into two tiers to better utilize storage resources, in which case, they would be implementing five tiers rather than four. Regardless of the configuration, the highest tier in this model -- Tier 0 -- always stores data for the most demanding workloads, and the lowest tier -- whether Tier 3, Tier 4, Tier 5 or something else -- stores the least critical and active data.
What is Tier 0 storage?
The top tier of the storage hierarchy traditionally started with Tier 1 storage, but the advent of solid-state and flash storage gave rise to the concept of Tier 0 storage. Tier 0 delivers greater performance than Tier 1 storage, and much of the data formerly considered Tier 1 is now stored on Tier 0.
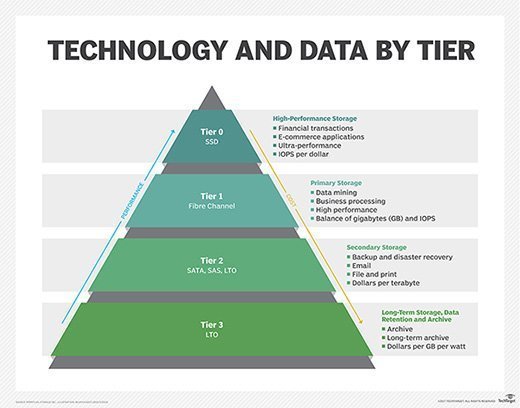
Tier 0 storage is the fastest and most expensive layer in the hierarchy and is suited for mission-critical applications with little tolerance for downtime or latency. Data placed in a "zero tier" often involves scale-up transactional databases for analytics, financials, healthcare and security.

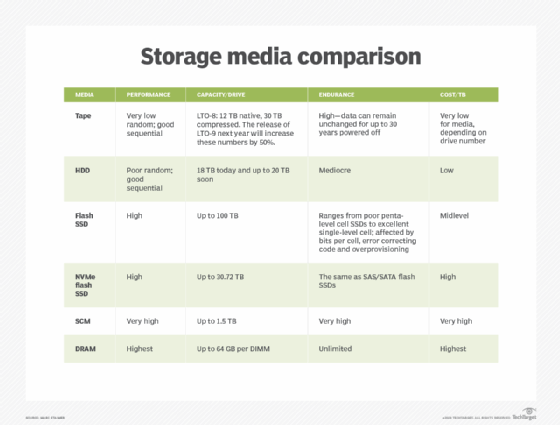
The storage devices that make up Tier 0 might include flash SSDs or storage class memory (SCM) devices such as Optane SSDs or memory modules. The SSDs typically use Peripheral Component Interconnect Express (PCIe) or non-volatile memory express (NVMe) technologies to maximize performance. In some cases, an organization might use single-level cell (SLC) flash for its performance and reliability. Tier 0 storage might also utilize Random Access Memory (RAM) to optimize performance.
Although Tier 0 storage is the most expensive type of storage, the tangible benefits of enhanced performance, such as faster time to market or increased sales, need to be weighed against the cost of Tier 0 storage devices.
What is Tier 1 storage?
Tier 1 data supports applications that are essential to an organization's ability to conduct its everyday business. Applications that rely on this data can usually tolerate higher latency and lower IOPS than Tier 0 applications. Storage costs are also more of a consideration than with Tier 0 storage, although Tier 1 still tends to use high-quality media -- such as double-parity RAID, to ensure the storage delivers the required latency and throughput, even if it's not as fast as Tier 0 storage.
Tier 1 storage might use SSDs, HDDs or a combination of both in a hybrid drive configuration. Hybrid storage systems cache hot data in flash for quick retrieval and write the remaining data to the HDDs. The HDDs used for Tier 1 storage tend to be the fastest and most expensive, especially if they're the sole type of storage being used at this tier.
In some cases, HDD-based storage will utilize a portion of the server's RAM to function as a virtual disk drive, especially if the HDDs are not part of a hybrid system. However, this also means less memory is available for compute resources. Additionally, RAM requires a constant power supply to retain its data. SSDs and HDDs are non-volatile memory (NVM) devices, so they can be disconnected from power and still retain their data.
Even if enterprises run most of their Tier 1 applications on spinning disk, they might still run select workloads on all-flash storage or on hybrid flash. In some cases, IT teams will take advantage of idle computing capacity to run transactional databases in fast in-memory storage. These devices include non-volatile dual in-line memory modules (NVDIMMs) that slide into a standard server slot.

What is Tier 2 storage?
Tier 2 storage is concerned with warm data, which might include old emails, classified files, historical financial information, or a variety of other types of information. This tier might also support reporting and analytics. Tier 2 storage typically requires greater capacity for longer durations, so the emphasis shifts from performance to cost-effectiveness.
Tier 2 storage often serves as an organization's secondary storage, hosting Tier 0 and Tier 1 backups as part of a business continuity and disaster recovery (BC/DR) strategy. Tier 2 storage makes it possible to quickly restore key files if data on the primary storage becomes unavailable.
The backup data on Tier 2 storage might include enterprise resource planning (ERP) systems, corporate email, back-office applications or any other application data that requires high reliability and security but doesn't need submillisecond latency.
Tier 2 data is preserved on lower-cost media that might include HDDs, backup appliances, tape storage or cloud storage. The HDDs are commonly based on SATA, rather than incorporating pricier RAID arrays or SAS devices. Recovery requirements often drive the type of media used for Tier 2 storage.
What is Tier 3 storage?
Tier 3 storage is an archive tier that sits behind the backup tier. The data in this tier is rarely accessed or updated, if at all. The tier's storage media might include slow-spinning HDDs, recordable compact discs, tape drives or archival cloud storage services -- whatever offers the least expensive storage compared to the other tiers. Tier 3 stores fixed copies of any content deemed to have a strategic value, however slight, or content that needs to be retained to comply with applicable regulations.
Many organizations direct backups to Tier 2 storage for a set period of time then move the data to a Tier 3 tape library for long-term retention. The data might be retained indefinitely or set to expire by a certain date. In some cases, archival data is written to disk only once and never erased or updated.
Companies in regulated industries use archives to migrate aging or inactive data off more expensive storage. Tier 3 storage supports compliance, historical analysis or other business needs that can arise periodically but don't require state-of-the-art storage.
Organizations are increasingly turning to object storage for their Tier 3 data, often implementing the tier as part of a hybrid cloud strategy that utilizes both on-premises systems and cloud services. The public cloud can store Tier 3 data as part of that hybrid strategy.
Some storage experts predict a future with fewer storage tiers, possibly only two, with primary data stored on a flash tier and archived and backup data placed in the cloud.
What is automated storage tiering?
Storage tiering started as a manual process, but automation has taken a greater role in both placing data and analyzing its placement. Since its introduction, tiering automation has continued to improve and evolve, with an increasing number of storage products now offering tiered storage capabilities, either built into the storage system or as third-party software or services.
Storage tiering automation grew increasingly important with the advent of hybrid storage arrays that mixed flash SSDs and HDDs. Automation ensures that only the most important data stays on expensive media and the rest is distributed accordingly.
Storage array vendors have now embedded automated storage tiering into the software management stack. Automated policies move data to the appropriate tier based on company-defined policies, typically in real time.
A number of third-party software vendors also offer management software that includes tiered storage. These products include software-defined Cloud storage gateways, copy data management and enterprise file sync-and-share suites.
What is optimized tiering?
Storage experts have said a well-developed data classification taxonomy is the linchpin to an optimized tiered storage architecture. A taxonomy classifies all data and balances costs against storage performance requirements.
Storage architects should clearly define the availability, performance and service attributes of each tier. The goal is to allow an application to choose the storage that aligns with the business tasks it carries out.
If a business depends on continuous uptime for its transaction processing applications, the revenue generated could more than cover the cost of high-performance storage. Storage tiering can enhance application performance by freeing up primary storage and moving secondary data to a lower-cost tier.
It is generally accepted that only 10% to 20% of data is considered "hot" at any given time. This means the fastest, most expensive storage should be dedicated solely to this frequently accessed data, with the remaining 80% to 90% stored on a cheaper tier of storage.
Tiering vs. caching
The terms storage tiering and data caching are often used interchangeably -- especially when dealing with flash media -- but they are different processes.
Caching places a temporary copy of the data on a high-performance medium, such as dynamic RAM (DRAM) or solid-state memory, to improve performance. The cache sits between the application and back-end storage.
The same data also resides on a lower storage tier, usually an HDD. The host software or storage controller copies the data to the cache, but the original copy of the data remains in its initial location.
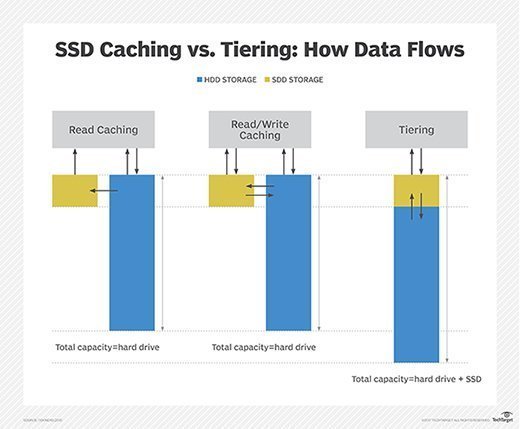
Tiered data resides on one media type at any time but moves between media as data access patterns change. Tiered storage does not copy data. It moves the data to a different storage medium, selecting the location that best balances availability, performance and the cost of the storage media. In this way, storage hardware can be better utilized, while still maximizing performance for mission-critical applications.







