unstructured data
What is unstructured data?
Unstructured data is information, in many different forms, that doesn't follow conventional data models, making it difficult to store and manage in a mainstream relational database.
The vast majority of new data being generated today is unstructured, prompting the emergence of new platforms and tools that are able to manage and analyze it. These tools enable organizations to more readily take advantage of unstructured data for business intelligence (BI) and analytics applications.
Unstructured data has an internal structure but does not contain a predetermined data model or schema. It can be textual or non-textual. It can be human-generated or machine-generated.
One of the most common types of unstructured data is text. Unstructured text is generated and collected in a wide range of forms, including Word documents, email messages, PowerPoint presentations, survey responses, transcripts of call center interactions and posts from blogs and social media sites.
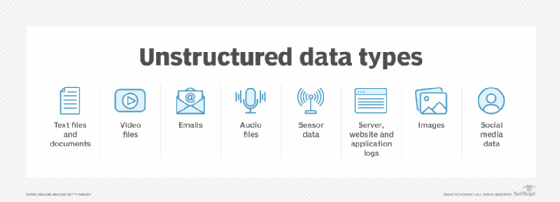
Other types of unstructured data include images, audio and video files. Machine data is yet another category of unstructured data, one that's growing quickly in many organizations. For example, log files from websites, servers, networks and applications -- particularly mobile ones -- yield a trove of activity and performance data. In addition, companies increasingly capture and analyze data from sensors on manufacturing equipment and other IoT connected devices.
Read more about the basics of unstructured data in "Storage 101: Unstructured data and its storage needs."
Structured vs. unstructured data
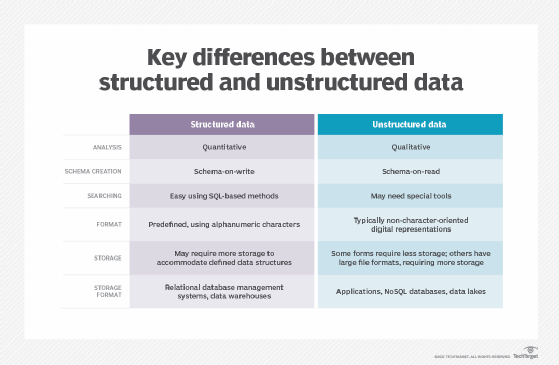
The main differences between structured and unstructured data include the type of analysis it can be used for, schema used, type of format and the ways it is stored. Traditional structured data, such as the transaction data in financial systems and other business applications, conforms to a rigid format to ensure consistency in processing and analyzing it. Sets of unstructured data, on the other hand, can be maintained in formats that aren't uniform.
Structured data is stored in a relational database (RDBMS) that provides access to data points that are related to one another via columns and tables. For example, customer information kept in a spreadsheet and categorized by phone numbers, addresses or other criteria is considered structured data.
Other examples of structured data systems include travel reservation systems, inventory registers and accounting remittance.
As this information is categorized, it's considered to be more searchable by both humans and algorithms in data analysis. Database administrators often use structured query language (SQL), which enables effective search queries of structured data in relational databases.
Oftentimes, structured data and unstructured data can be used together. For example, a structured spreadsheet of customer data could be imported to an unstructured customer relationship management (CRM) system.
What is semistructured data?
Semistructured data is largely unstructured but uses internal tags and markings that separate and differentiate various data elements, placing them into pairings and hierarchies.
Email is a common example. The metadata used in an email enables analytics tools to classify and search easily for keywords. Sensor data, social media data, markup languages like XML and NoSQL databases are examples of unstructured data that are evolving for greater searchability and may be considered semistructured data.
What is unstructured data used for?
Because of its nature, unstructured data isn't suited to the transaction processing applications that often handle structured data. Instead, it's primarily used for BI and analytics. One popular application is customer analytics. Retailers, manufacturers and other companies analyze unstructured data to improve customer experience and enable targeted marketing. They also do sentiment analysis to better understand customers and identify attitudes about products, customer service and corporate brands.
Predictive maintenance is an emerging analytics use case for unstructured data. For example, manufacturers can analyze sensor data to detect equipment failures before they occur in plant-floor systems or finished products in the field. Energy pipelines can also be monitored and checked for potential problems using unstructured data collected from IoT sensors.
Analyzing log data from IT systems highlights usage trends, identifies capacity limitations and pinpoints the cause of application errors, system crashes, performance bottlenecks and other issues. Unstructured data analytics also aids regulatory compliance efforts, particularly in helping organizations understand what corporate documents and records contain.
Unstructured data techniques and platforms
In the past, unstructured data was often locked away in siloed document management systems, individual manufacturing devices and the like -- making it what's known as dark data, unavailable for analysis.
But things changed with the development of big data platforms, primarily Hadoop clusters, NoSQL databases and the Amazon Simple Storage Service (S3). They provide the required infrastructure for processing, storing and managing large volumes of unstructured data without the need for a common data model and a single database schema.
Next-generation unstructured data analysis tools
A variety of analytics techniques and tools are used to analyze unstructured data in big data environments. Other techniques that play roles in unstructured data analytics include data mining, machine learning and predictive analytics.
Text analytics tools look for patterns, keywords and sentiment in textual data. At a more advanced level, natural language processing technology is a form of artificial intelligence that seeks to understand meaning and context in text and human speech, increasingly with the aid of deep learning algorithms that use neural networks to analyze data.
Newer tools can aggregate, analyze and query all data types to enable greater insight into corporate data and improved decision-making. Examples include the following:
Learn more about how your organization can use unstructured data to its benefit in "Managing unstructured data to boost performance, lower costs."







