Storage

.shock - Fotolia
Building an IT resiliency plan into an always-on world
A multipronged approach is the best protection against unaffordable and unacceptable downtime in today's 24/7 business cycle.

The concepts of recovery point objectives and recovery time objectives are becoming increasingly obsolete. Today's highly connected world has forced most organizations to ensure IT resiliency and make their resources continuously available. More importantly, the cost of downtime continues to increase and has become unacceptable and even unaffordable for many organizations.
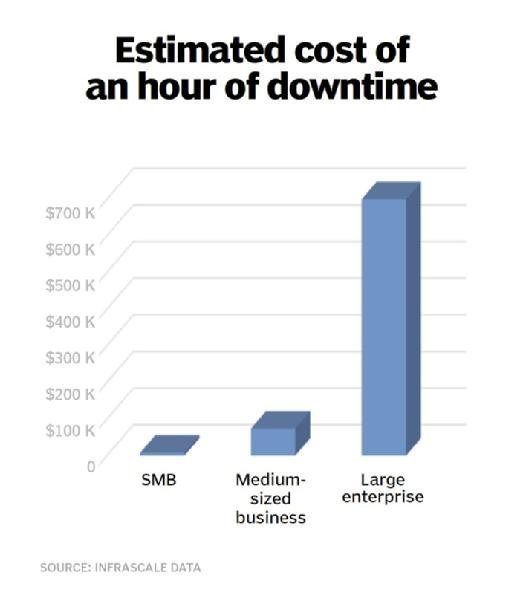
A 2016 study by the Ponemon Institute estimated the total cost of data center downtime to be about $740,357 per hour -- a little higher than a similar 2015 study by cloud backup and disaster recovery-as-a-service provider Infrascale. The study also indicated that downtime can be so expensive, it calculated data center outages cost businesses an average of $8,851 per minute.
For large companies, the losses can be staggering. One 2016 outage cost Delta Air Lines $150 million.
The study went on to state that it takes, on average, 18.5 hours for a business to recover from a disaster. Given the hourly price of an outage, the cost of recovering from a disaster can be staggering. So it is hardly surprising the IT industry is transitioning from legacy backup and recovery planning in favor of disaster recovery or business continuity planning.
Making resources continuously available and focusing on IT resiliency to avoid failure requires extensive planning. The key is to determine the points at which failures are likely to occur, and then develop contingency plans. There is no silver bullet solution that will provide complete protection against failure. Instead, IT pros should focus on multi-tier processes that establish protection in depth.
Implementing redundancy in the data center
The first step in establishing an IT resiliency plan is to identify potential problems that could result in an outage, and then use redundancy as a countermeasure. To provide a simple example, organizations routinely protect themselves against hard disk failure by using disk mirroring. Similarly, you may leverage failover clustering to guard against a node-level failure or backup generators to protect against power failures.
As important as redundancy is, however, that alone will not provide true IT resiliency. Even if every component in the entire data center is protected by a redundant component, the data center itself can become a point of failure.
Establishing
Organizations must have a way of continuing to operate normally following an event that results in primary data center incapacitation or even destruction. At its simplest, this means being able to shift operations to an alternate facility.
You can accomplish this several ways. One popular option is to use distance clustering. The basic idea behind this technique is that a failover cluster can be stretched, and cluster nodes can be placed into a remote data center. If a data center-level failure occurs, then highly available workloads running on the cluster could automatically fail over to the remote facility.
Although distance clustering is a mature technology, you may find it difficult to implement. The requirements vary not just among vendors, but also from one software version to the next. Typically, however, some of the more pressing issues to plan for include adhering to the cluster's distance and latency requirements, arranging cluster nodes with regard to Quorum -- while also preventing split brain syndrome -- and providing storage connectivity to the cluster nodes.
Another technique sometimes used to ensure data center resiliency is storage replication, provided by vendors such as Dell EMC and NetApp. Replication does not have to occur at the storage appliance level, though. Hypervisor vendors such as Microsoft and VMware include built-in replication that takes hardware-agnostic approaches. By doing so, it becomes possible to replicate virtual machines (VMs) either to an alternative data center or to the cloud.
Do host or guest clusters provide better protection?
Admins often debate whether to use VM host or guest clusters for availability.
Prior to server virtualization, application clusters -- an application designated with a clustered role on a Windows failover cluster -- primarily ensured application availability. However, major hypervisor vendors such as VMware and Microsoft now provide clustering capabilities at the virtualization host level, thereby allowing virtual machines to fail over to an alternate host in the event of a host-level failure. This technology can make nearly any VM highly available:
- Guest clusters mimic legacy clusters that make applications highly available. These failover clusters nodes run on virtual servers instead of dedicated physical hardware.
- Host clusters, on the surface, seem to eliminate the need for guest clusters, because they provide high availability to the VMs running within the cluster, independently of any application-level protective mechanisms. It is important to consider however, that virtual machine host clusters protect VMs against host-level failures. They do nothing to protect applications against VM-level failures. Guest clustering provides an extra degree of protection by extending high availability to the application, not just to a VM.
Not every workload supports clustering, but it is in your best interest to enable guest clustering for any workload that can be made highly available. In addition, hypervisors should also be clustered (host clustering), so as to protect VMs against physical server failures.
You can also protect against failure through erasure coding. erasure coding works similarly to array parity, except only data is striped across multiple data centers or across multiple clouds. It provides two distinct benefits. First, it allows you to store multiple copies of data in remote locations. Administrators can usually specify the number of redundant copies required or the number of failures that potentially need to be tolerated.
The other advantage of erasure coding is it can help ensure sensitive data remains secure. If an organization decides to store data in the public cloud, then erasure coding can structure that data so no one single cloud provider has a complete copy. Instead, erasure coding scatters data fragments across multiple clouds, with enough redundancy to allow for one or more cloud-level failures to occur without an interruption in service.
Continuous backup and instant recovery
Although there's been an increased emphasis on replication and continuous availability in recent years, backup and recovery remain critically important. Although replication creates redundant copies of organizational resources, redundancy does not mitigate the need for point-in-time recovery. For example, if ransomware encrypts data within an organization's primary data center, then all data affected would be quickly replicated to all redundant copies. The only practical way to undo the damage would be to restore the data to an earlier point in time.
Although backup and recovery have existed in various forms for decades, an "always-on" environment requires continuous data protection with instant recovery capabilities.
Storage resiliency in Windows Server 2016
Although often overlooked in lists of new OS features, Microsoft designed Windows Server 2016 to be resilient to transient storage failures. That's because, with the exception of hyper-converged infrastructure deployments, virtualization hosts rarely store VMs on local storage. As such, the connectivity to an external storage array can become a point of failure.
In Windows Server 2012 R2 and earlier Windows Server OSes, a Hyper-V virtual machine encountering a failure while reading or writing to a virtual hard disk would crash.
In Windows Server 2016, however, a protective mechanism guards against short-term storage failures. If a VM suddenly cannot read to or write from its virtual hard disk, then the hypervisor will perform an action that's similar to what happens when a VM snapshot is created. The hypervisor "freezes" the VM, thereby preserving the virtual machine's state.
When storage becomes available again the VM is "thawed," and its operations continue as if nothing ever happened. While it's true a VM isn't accessible to end users while frozen, short, transient failures that would have previously caused a crash will now likely go unnoticed.
Continuous data protection is commonly based on changed block tracking. If a storage block is created or modified, then the block is targeted for backup. Rather than performing a single, monolithic backup during off-peak hours as was once common, the data is backed up on a continuous basis, either synchronously or asynchronously.
Instant recovery allows you to recover one or more VMs almost instantly, without having to wait for a traditional restoration to complete. Instant recovery is based on the idea that most enterprises are highly virtualized and complete copies of VMs exist within backup targets. As such, an organization that needs to perform a recovery operation can mount a VM -- from a predetermined point in time -- directly from the backup target. This allows instant accessibility to data, while more traditional restoration takes place in the background.
In an effort to preserve the integrity of the backups, any write operations occurring within a VM running from backup redirect to a dedicated virtual hard disk, typically a child virtual hard disk that is attached to a snapshot of the VM's primary virtual hard disk. This prevents the backup copy of the VM from being modified. When full restoration completes, the write operations that have occurred since the instant recovery began are merged onto the VM's virtual hard disk. At that point, user sessions are redirected from the backup VM to the newly restored primary VM.
Today, most major backup vendors, including Veritas, Commvault and Veeam, offer instant recovery.
Developing an IT resiliency plan involves much more than merely implementing a technology that is designed to provide continuous availability. The only way to achieve true IT resiliency is to practice protection in-depth by implementing countermeasures such as data center failover and instant recovery capabilities to any potential point of failure.