data deduplication
What is data deduplication?
Data deduplication is a process that eliminates redundant copies of data and reduces storage overhead.
Data deduplication techniques ensure that only one unique instance of data is retained on storage media, such as disk, flash or tape. Redundant data blocks are replaced with a pointer to the unique data copy. In that way, data deduplication closely aligns with incremental backup, which copies only the data that has changed since the previous backup.
An example of data deduplication
A typical email system might contain 100 instances of the same 1 megabyte (MB) file attachment. If the email platform is backed up or archived, all 100 instances are saved, requiring 100 MB of storage space. With data deduplication, only one instance of the attachment is stored; each subsequent instance is referenced back to the one saved copy.
In this example, a 100 MB storage demand drops to 1 MB.
Target vs. source deduplication
Data deduplication can occur at the source or target level.
Source-based dedupe removes redundant blocks before transmitting data to a backup target at the client or server level. There is no additional hardware required. Deduplicating at the source reduces bandwidth and storage use.
In target-based dedupe, backups are transmitted across a network to disk-based hardware in a remote location. This deduplication increases costs, although it generally provides a performance advantage compared to source dedupe, particularly for petabyte-scale data sets.
Techniques to deduplicate data
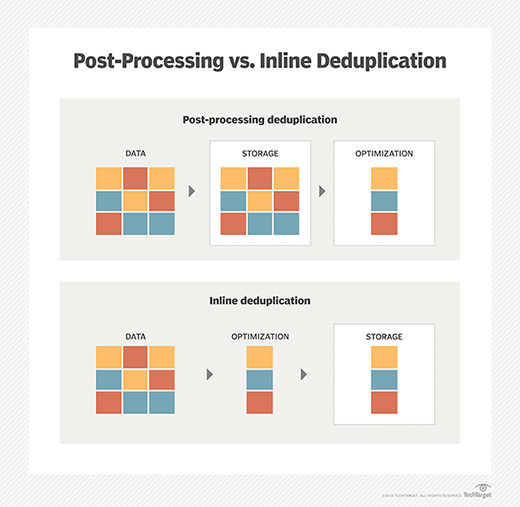
There are two main methods to deduplicate redundant data: inline and post-processing deduplication. The backup environment will dictate the method.
Inline deduplication analyzes data as a backup system ingests it. Redundancies are removed as the data is written to backup storage. Inline dedupe requires less backup storage but can cause bottlenecks. Storage array vendors recommend that users turn off their inline data deduplication tools for high-performance primary storage.
Post-processing dedupe is an asynchronous backup process that removes redundant data after it is written to storage. Duplicate data is removed and replaced with a pointer to the first iteration of the block. The post-processing approach gives users the flexibility to dedupe specific workloads and quickly recover the most recent backup without hydration. The tradeoff is a larger backup storage capacity than is required with inline deduplication.
File-level vs. block-level deduplication
Data deduplication generally operates at the file or block level.
File-level data deduplication compares a file to be backed up or archived with copies that are already stored. This is done by checking its attributes against an index. If the file is unique, it is stored and the index is updated; if not, only a pointer to the existing file is stored. The result is only one instance of the file being saved. Subsequent copies are replaced with a stub that points to the original file.
Block-level deduplication looks within a file and saves unique iterations of each block. All the blocks are broken into chunks with the same fixed length. Each chunk of data is processed using a hash algorithm, such as MD5 or SHA-1.
This process generates a unique number for each piece, which is then stored in an index. If a file is updated, only the changed data is saved, even if only a few bytes of the document or presentation have changed. The changes don't constitute an entirely new file. This behavior makes block deduplication more efficient than file deduplication. However, block deduplication takes more processing power and uses a larger index to track the individual pieces.
Variable-length deduplication is an alternative that breaks a file system into chunks of various sizes, letting the deduplication effort achieve better data reduction ratios than fixed-length blocks. However, it also produces more metadata and runs slower.
Benefits and a drawback to deduplication
Hash collisions are a potential problem with deduplication. When a piece of data receives a hash number, that number is then compared with the index of other existing hash numbers. If that hash number is already in the index, the piece of data is considered a duplicate and does not need to be stored again. Otherwise, the new hash number is added to the index and the new data is stored.
In rare cases, the hash algorithm may produce the same hash number for two different chunks of data. When a hash collision occurs, the system won't store the new data because it sees that its hash number already exists in the index. This is called a false positive, and it can result in data loss. Some vendors combine hash algorithms to reduce the possibility of a hash collision. Some vendors are also examining metadata to identify data and prevent collisions.
Benefits of deduplication include the following:
- a reduced data footprint;
- lower bandwidth consumption when copying data associated with remote backups, replication and disaster recovery;
- longer retention periods;
- faster recovery time objectives; and
- reduced tape backups.
Data deduplication vs. compression vs. thin provisioning
Another technique often associated with deduplication is compression. However, the two techniques operate differently. Data dedupe seeks out redundant chunks of data while compression uses an algorithm to reduce the number of bits needed to represent data.
Compression and Delta differencing are often used with deduplication. Taken together, these three data reduction techniques are designed to optimize storage capacity.
Thin provisioning optimizes how a storage area network uses capacity. Conversely, erasure coding is a method of data protection that breaks data into fragments and encodes each fragment with redundant data pieces to reconstruct corrupted data sets.
Deduplication of primary data and the cloud
Data deduplication originated in backup and secondary storage, although it is possible to dedupe primary data sets. It is particularly helpful to maximize flash storage capacity and performance. Primary storage deduplication occurs as a function of the storage hardware or operating system software.
Techniques for data dedupe hold promise for cloud services providers rationalizing expenses. The ability to deduplicate what they store results in lower costs for disk storage and bandwidth for off-site replication.
This article was last updated by Garry Kranz in 2019. TechTarget editors revised it in 2022 to improve the reader experience.







