Kilo, mega, giga, tera, peta, exa, zetta and all that

What is kilo, mega, giga, tera, peta, exa, zetta and all that?
Kilo, mega, giga, tera, peta, exa and zetta are among the binary prefixes used to denote the quantity of something, such as a byte or bit in computing and telecommunications. Sometimes called prefix multipliers, these prefixes are also used in electronics and physics.
In communications, electronics and physics, multipliers are defined in powers of 10, from 10-24 to 1024, proceeding in increments of three orders of magnitude -- 103 or 1,000. In IT and data storage, multipliers are defined in powers of two, from 210 to 280, proceeding in increments of 10 orders of magnitude -- 210 or 1,024.
Examples of quantities or phenomena in which power-of-10 prefix multipliers apply include frequency -- including computer clock speeds -- physical mass, power, energy, electrical voltage and electrical current. Power-of-10 multipliers are also used to define binary data speeds. For example, 1 kilobit per second (kbps) is equal to 103, or 1,000 bits per second (bps); 1 megabit per second (Mbps) is equal to 106, or 1,000,000 bps. The lowercase k is the technically correct symbol for kilo when it represents 103, although the uppercase K is often used.
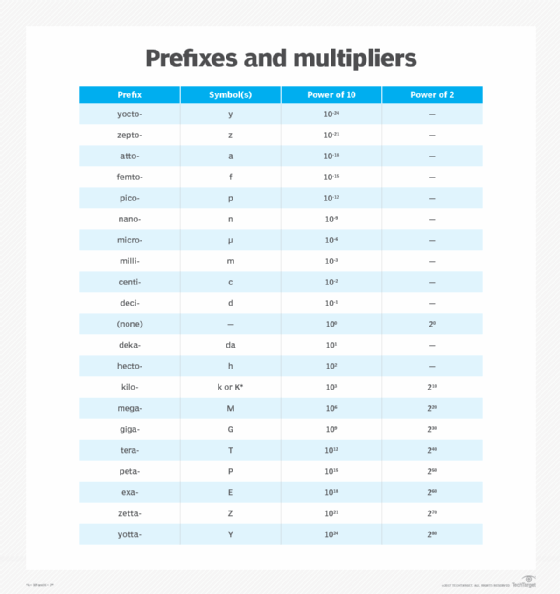
When binary data is stored in memory or fixed media, such as a hard disk or drive, magnetic tape or CD-ROM, power-of-two multipliers are used. Technically, the uppercase K should be used for kilo when it represents 210. Therefore, 1 kilobyte (KB) is 210, or 1,024 bytes; 1 megabyte (MB) is 220, or 1,048,576 bytes.
The choice of power-of-10 versus power-of-two prefix multipliers can appear random. It helps to remember that multiples of bits are almost always expressed in powers of 10, while multiples of bytes are usually expressed in powers of two. Data speed is rarely expressed in bytes per second, and data storage or memory is seldom expressed in bits.
History and origin of kilo, mega and more
The prefix kilo (1,000) first came into existence between 1865 and 1870. Though mega is used these days to mean "extremely good, great or successful," its scientific meaning is 1 million.
Giga comes from the Greek word for giant, and the first use of the term is believed to have taken place at the 1947 conference of the International Union of Pure and Applied Chemistry. Tera (1 trillion) comes from the Greek word teras or teratos, meaning "marvel, monster," and has been in use since approximately 1947.
The prefixes exa (1 quintillion) and peta (1 quadrillion) were added to the International System of Units (SI) in 1975. However, the origin and history of peta with data measurement terms is unclear. Zetta (1 sextillion) was added to the SI metric prefixes in 1991.
Examples of -byte sizes
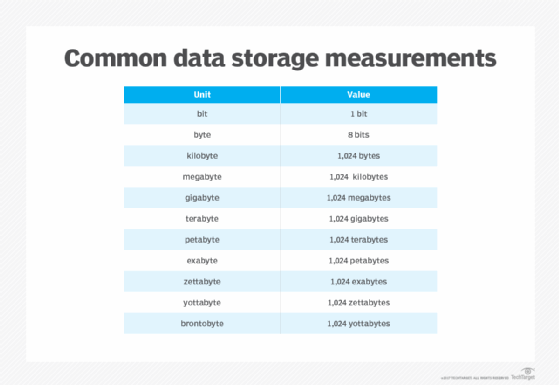
When the prefixes are added to the term byte, it creates units of measurement ranging from 1,000 bytes (kilobyte) to 1 sextillion bytes (zettabyte) of data storage capacity.
A gigabyte (GB) is equivalent to about 1 billion bytes. There are two standards for measuring the number of bytes in a gigabyte: base-10 and base-2. Base-10 uses the decimal system to show that 1 GB equals one to the 10th power of bytes, or 1 billion bytes. This is the standard most data storage manufacturers and consumers use today. Computers typically use the base-2, or binary, form of measurement. Base-2 has 1 GB as equal to 1,073,741,824 bytes. The discrepancy between base-10 and base-2 measurements became more distinct as vendors began to manufacture data storage media with more capacity.
A terabyte (TB) is equal to approximately 1 trillion bytes, or 1,024 GB. A petabyte (PB) is equal to two to the 50th power of bytes. There are 1,024 TB in a PB, and about 1,024 PB equal 1 exabyte (EB). A zettabyte is equal to about 1,000 EB, or 1 billion TB.
Real-world examples of measurements
When it comes to quantifying just how much data storage capacity is offered by kilobytes, megabytes and so on, consider the following chart:
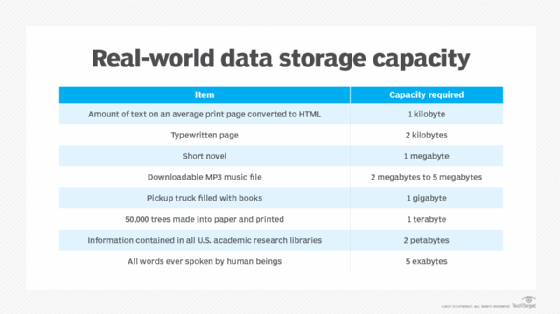
In his book, The Singularity is Near, futurist Raymond Kurzweil estimated the capacity of a human being's functional memory to be 1.25 TB. This means that the memories of 800 human beings fit into 1 PB of storage.
If the average MP3 encoding is approximately 1 MB per second (MBps), and the average song lasts about four minutes, then a petabyte of songs could play continuously for more than 2,000 years. If the average smartphone camera photo is 3 MB, and the average printed photo is 8.5-inches wide, a petabyte of photos placed side by side would be more than 48,000 miles long. That is almost long enough to wrap around the equator twice.
To count all the bits in 1 PB of storage at a rate of 1 bps would take 285 million years, according to data analysts from Deloitte Analytics. A bit is a binary digit, either a 0 or 1; a byte is eight binary digits long.
Yottabytes and data storage
The future of data storage may be the yottabyte. It's a measure of storage capacity equal to approximately 1,000 zettabytes, 1 trillion terabytes, a million trillion megabytes or 1 septillion bytes.
Written in decimal form, a yottabyte looks like this: 1,208,925,819,614,629,174,706,176. The prefix yotta is based on the Greek letter iota. According to Paul McFedries' book Word Spy, it would take 86 trillion years to download a 1 yottabyte file; by comparison, the entire contents of the Library of Congress would equal just 10 TB.
See Kibi, mebi, gibi, tebi, pebi and all that, which are relatively new prefixes designed to express power-of-two multiples.
Editor's note: This article was written by Ed Hannan in 2019. TechTarget editors revised it in 2022 to improve the reader experience.






